The first three articles in this series dealt with special and general relativity, the two great twentieth-century theories of the geometry of spacetime and its relationship with matter and energy. This article will describe the ideas behind a second, simultaneous revolution in physics, one that has had even more profound philosophical and technological consequences: quantum mechanics.
The Birth of Quantum Mechanics
In the second half of the nineteenth century, the Newtonian description of the dynamics of material objects was supplemented by an equally successful theory encompassing all of electrostatics, magnetism and optics. The physicist James Clerk Maxwell brought together a number of disparate laws that had been found to govern quite specific phenomena – such as the force between two motionless electric charges – into a unified description of an electromagnetic field. Light, and most other forms of radiation, were seen to consist of oscillations in this field, or electromagnetic waves. This confirmation of the wave-like nature of light made sense of many long-standing observations, including the phenomenon of interference: if you allow light of a single wavelength to travel through two adjacent narrow slits in a barrier and then recombine on a screen, it produces patterns of dark and light stripes. Since the difference in the time it takes for light waves from the two slits to reach the screen varies from place to place, the waves shift in and out of phase with each other, resulting in varying degrees of constructive interference (where the contributions to the field from both slits point in the same direction), and destructive interference (where they point in opposite directions).

Newtonian dynamics and Maxwellian electrodynamics cut a wide swath through the scientific problems of the day. However, by the end of the nineteenth century a number of serious discrepancies had been found between experimental results and predictions based on these two theories. Newtonian physics was soon to be superseded by special relativity, but the most glaring problems had nothing to do with the motion of objects at high velocities, so the explanation had to lie in another direction entirely.
One of the biggest puzzles involved the spectrum of radiation emitted by hot objects: thermal radiation. This is visible to the naked eye when, for example, the tungsten wire in a light bulb becomes white hot. There’s an idealised class of objects for which this effect is particularly easy to analyse: if an object is a perfect absorber and emitter of electromagnetic waves across the entire spectrum, its thermal radiation should depend solely on its temperature, rather than any idiosyncratic properties of the stuff from which it’s made. Physicists call this a black body, since it should appear black to the naked eye at room temperature. The cavity of a furnace containing nothing but the thermal radiation from its heated walls, with a tiny hole through which radiation can escape to be observed, serves as a good approximation to a black body, both theoretically and experimentally, so black body thermal radiation is also known as cavity radiation.
Maxwell’s theory suggested that the electromagnetic field inside a cavity should be treated as something akin to the three-dimensional equivalent of a piano string being bashed at random, simultaneously vibrating with every possible harmonic. A piano string has evenly spaced harmonics, say 500 Hz, 1000 Hz, 1500 Hz, and so on, which occur when an exact number of half-wavelengths fit the length of the string; the fact that the ends of the string are fixed prevents other frequencies being produced. An electromagnetic field in a three-dimensional cavity is subject to similar boundary conditions, but unlike a piano string the field’s vibrations are free to point in different directions. For example, the field in a cubical cavity might vibrate in such a way that 5, 7 and 4 half-wavelengths span the cavity’s width, breadth and height respectively, because of the way the waves are oriented with respect to the walls. But waves of exactly the same frequency, oriented differently, would fit just as well with 4, 5 and 7 half-wavelengths spanning the same three dimensions.

This makes the situation more complicated than it is for a piano string, but it’s still not too hard to count the modes available to the field: the number of distinct ways in which it can vibrate. Figure 2 isn’t a drawing of a furnace cavity; rather, each point here represents a different mode, with the x, y and z coordinates of the point giving the number of half-wavelengths that fit across the width, breadth, and height of the cavity. The more tightly packed the waves are, the shorter their wavelength and the greater their frequency. The exact frequency of any mode is proportional to its distance from the centre of the diagram – that’s just a matter of Pythagoras’s theorem, and the relationship between frequency and wavelength. So the number of points between the two spherical shells counts the number of modes in the frequency range ΔF. For small values of ΔF, this is proportional to the surface area of the inner sphere, which is proportional to F2.
Because the walls of the cavity are assumed not to favour any particular frequency, every possible mode of the electromagnetic field should have, on average, an equal share of the total energy. The trouble is, the field has an infinite number of modes – at ever higher frequencies, you just keep finding more of them. If the energy from the furnace really was free to spread itself between them, giving them all an equal share, that would be a never ending process, like gas escaping into an infinite vacuum. The average frequency of the radiation in the cavity would wander off towards the ultraviolet and beyond, never stabilising at any fixed spectrum.

The reality is nothing like this, as Figure 3 shows. The observed spectrum reaches a peak at a certain frequency, then tapers off. Clearly, something prevents the energy of the field from being equally distributed amongst all possible modes. But what?
The analysis we’ve given so far assumes that energy can be spread as thinly as you like; as more and more modes share the energy of the field, each one ends up, individually, with a smaller amount. But what if energy couldn’t be endlessly subdivided like this? What if you eventually reached a minimum amount, a “particle” of energy, as indivisible as some particles of matter presumably are? Instead of taking on any value whatsoever, energy would only be found in exact multiples of this amount.
In 1900, Max Planck proposed that this was the case, and called the minimum amount a quantum. Though it might have been simplest to decree a fixed amount of energy as the size of one quantum, like the fixed mass of an electron, that wouldn’t have solved the cavity radiation problem: with an infinite number of modes available, the finite number of quanta would still have been free to “escape” to ever higher frequencies. The only way to prevent this was to propose that higher frequency modes required a greater minimum energy than lower frequency modes, raising a series of ever higher hurdles to counteract the tendency for the energy to spread. Planck found that making the energy of one quantum proportional to the frequency of the electromagnetic wave, as in Equation (1), would yield a spectrum precisely in agreement with observation, if the constant of proportionality was chosen correctly. This value, now known as Planck’s constant, is referred to by the letter h, and has a value of 6.625×10–34 Joules per Hz.
| E | = | h F | (1) |
You might be wondering how Equation (1) dictates the nice tapered curve in Figure 3. What’s to stop all the energy in the furnace from going into a single, super-high-frequency quantum, making the spectrum an isolated peak way off to the right of the graph? The same thing that stops all the energy in the Earth’s atmosphere from ending up concentrated in a couple of atoms: it’s just not very likely. Of all the possible ways a certain total amount of energy can be distributed between billions of possible modes of cavity radiation, the vast majority look like the curve in Figure 3.
Over the first three decades of the twentieth century, many other experiments confirmed the quantisation of light, and led independently to the same value for Planck’s constant. One famous example is the photoelectric effect. When ultraviolet light is shone on a metal plate in a vacuum tube it blasts electrons off the surface of the metal. The energy of the individual electrons released this way (as opposed to the total energy they possess en masse) turns out to be completely independent of the intensity of the light shone on the plate, and can only be increased by using light of a greater frequency. This makes sense if the electrons are absorbing individual quanta, rather than gaining energy from the electromagnetic field as a whole. More intense light of a given frequency contains more quanta of the same energy, and can blast more electrons off the plate – but only raising the frequency of the light, and hence the energy of the quanta, can increase the energy of each individual electron.
Quanta of light, which came to be known as photons, were shown again and again to behave like localised, indivisible particles. But there was no denying the fact that light also behaved like a wave, exhibiting interference effects. Neither aspect could be ignored, but it was not at all clear how to synthesise the two into a coherent new description of electromagnetism.
In parallel with these revelations about light, physicists were grappling with the problem of the structure of atoms. Electrons had been discovered in 1897, and in 1911 Ernest Rutherford had found strong experimental evidence for the theory, first proposed by Hantaro Nagaoka, that atoms consisted of electrons orbiting a positively charged nucleus. The puzzle here was that charged particles moving in a circle emit electromagnetic waves, so the electron should have radiated away all its energy and plunged into the nucleus. Not even Planck’s quantised photons could rule this out.
In 1913, Neils Bohr proposed that the energy of the electrons themselves was quantised, and the existence of a minimum allowed energy kept them from falling into the nucleus. Bohr came up with a formula for the energy levels of the single electron in a hydrogen atom, constructed in order to agree with the observed spectrum of light emitted and absorbed by hydrogen. This spectrum consisted of a discrete set of sharply defined frequencies, which could now be interpreted as the frequencies of photons whose energies matched the differences in energy between the allowed states of the electron. An electron could only move to a higher energy level by absorbing a photon that provided exactly the right amount of energy, and it could only drop back to a lower level by emitting a photon that carried the energy away again. This was by far the most successful model of atomic structure to date, but Bohr’s formula was even more mysterious than Planck’s. Why were only certain energy levels available to the electron?
The first hint at an answer came from the suggestion by Louis de Broglie in 1924 that matter, as well as radiation, might behave like both a wave and a particle. This was confirmed spectacularly a few years later, in experiments showing that electrons fired at a crystal were reflected back most often in certain directions: those in which a wave that scattered off the regularly spaced atoms of the crystal would undergo constructive interference. Since then, interference effects have been demonstrated for all kinds of particles, including entire atoms.
To examine de Broglie’s idea more closely, we need to ask what the wavelength and frequency of the “matter wave” associated with a particle should be. One reasonable starting point is the relationship that worked so successfully for Planck with photons: E=h F. Since F is the frequency of the wave (the number of oscillations per second), the period of the wave, the time each oscillation takes, is:
| T | = | 1/F | |
| = | h/E | (2) |
Since the wave for a photon is moving forward through space at the speed of light, c, each cycle is spread out over one wavelength:
| L | = | c T | |
| = | c h/E |
Throughout these articles we’ve been using units where c=1, but it’s worth leaving the c in here for a moment, and stating the fact that the momentum, p, of a photon with energy E is always p=E/c. (This must be true in order for the 4-momentum of the photon to be a null vector, a spacetime vector with an overall length of zero, as discussed in the previous article. The relationship is obvious when c=1, but it holds regardless of the units used.) So the wavelength of light is related to each photon’s momentum by:
| L | = | h/p | (3) |
Equations (2) and (3) are the formulas de Broglie proposed for the period and wavelength of matter waves. Let’s see what such a wave might look like on a spacetime diagram.
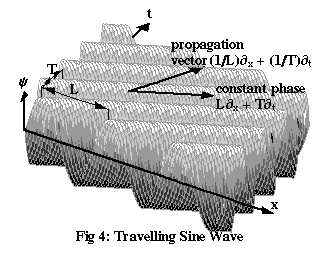
Figure 4 shows a travelling sine wave with period T and wavelength L. We don’t actually know that a matter wave will ever take the form of a sine wave, but we might as well start with a simple possibility like this and see where it leads us. The third axis on the diagram represents the “strength” of the wave, or amplitude, traditionally labelled ψ (the Greek letter psi). Exactly what ψ means, physically, is something we’ve yet to determine. The equation for ψ in terms of x and t, the wave function, is:
| ψ(x,t) | = | sin(2π(x/L – t/T)) | (4a) |
| = | sin(2π(px – Et)/h) | (4b) |
It’s not hard to see that the wave defined by Equation (4a) will go through a complete cycle whenever x increases by one wavelength, L, or time increases by one period, T. The expression 2π(x/L – t/T) is known as the phase of the wave: each individual peak (or trough) in Figure 4 has a certain constant phase, and successive peaks (or troughs) have a phase of 2π more than the last one. The minus sign here, rather than a plus sign, guarantees that a peak of the wave will move in the positive x direction: to keep 2π(x/L – t/T) constant, x must increase as t increases.
If we define the propagation vector for the wave, k, as:
| k | = | (1/L)∂x + (1/T)∂t |
and we write x = x∂x + t∂t for the spacetime vector that points from the origin to any event in flat spacetime, then using the Minkowskian metric, g, we can rewrite Equations (4) as:
| ψ(x) | = | sin(2π g(x,k)) | (5a) |
| = | sin(2π g(x,P)/h) | (5b) |
where P is the particle’s 4-momentum, p∂x + E∂t. Observers with different velocities must agree on the value of g for two spacetime vectors, so they’ll find nothing to argue about in Equations (5), despite measuring different individual x and t coordinates for all the vectors involved. And having defined the propagation vector like this, the relationship between wave and particle can be summed up in a single equation, a “spacetime version” of Planck’s Equation (1):
| P | = | h k | (6) |
The propagation vector, k, is perpendicular in the spacetime sense to the peaks and troughs of the waves, the wavefronts for which the phase remains constant. For light waves, since the 4-momentum P and the propagation vector k are null vectors, “perpendicular to themselves” in the sense that g(k,k)=g(P,P)=0, they’re actually both parallel and perpendicular to the wavefronts. Null vectors are like that.
For matter waves, since P and k are timelike vectors, the wavefronts perpendicular to them must be spacelike – which means the peaks and troughs of these waves will seem to “travel” faster than light. If the 4-momentum P is that of a particle with a speed of v, the phase of the wave will have an apparent “speed” of 1/v. For example, a particle moving at 50% of lightspeed will be described by a wave with peaks that “move” at twice the speed of light.
At first glance this might seem like either a disastrous mistake in the theory, or an opportunity for sending signals faster than light, but in fact it’s neither. Long before quantum mechanics, the study of waves revealed a crucial distinction between the phase velocity, which describes how the peaks and troughs of a wave seem to move, and the group velocity, which describes how disturbances in air, water, and other media actually propagate from one place to another. For light in a vacuum these two velocities are identical, but that situation is really quite rare.
How can the peak of a wave merely “seem to move”? Imagine setting up a long row of suspended weights bouncing on the ends of springs, all of them bouncing with exactly the same frequency, but with each weight reaching its highest point a fraction of a second later than its neighbour on the left. These weights will form a travelling sine wave just like the one in Figure 4, and in principle there’s nothing to stop you arranging the time lags so that the peaks “travel” as fast as you like from left to right, even faster than light. But nothing whatsoever is passing from one spring to the next as this happens. Of course, real waves do spread by transmitting their “bounce” from place to place, but the speed at which that happens need not be the same as the apparent “speed” of their peaks and troughs, which simply measures the fact that different parts of the wave are out of synch.
To make the idea of group velocity more concrete, let’s construct a new de Broglie wave by adding together several waves, all of the form given by Equations (4), but with a range of different frequencies. In the region where all these waves are more or less in phase with each other, they’ll produce a kind of mound, or wave packet.
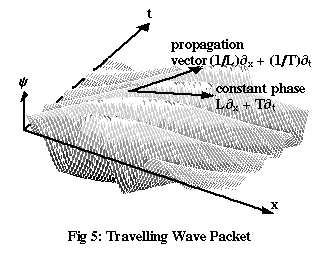
Figure 5 shows the result of adding waves of both higher and lower frequencies to the original wave of Figure 4. The overall height of the wave packet, ignoring the individual dips and rises and just looking at an “envelope” stretching from peak to peak, is greatest at the point where all the waves are perfectly in phase with each other – but it’s clear that this point doesn’t move at the same speed as the individual peaks. So how fast does it move?
Start with a simple fact that we established in the previous article: the length of a particle’s 4-momentum vector P is just its rest mass, m, and hence m2=–g(P,P)=E2–p2. Two waves with slightly different energies and momenta – say E1 and E2, p1 and p2 – that happen to be in phase will only stay in phase where (p1x – E1t) remains equal to (p2x – E2t), since apart from factors of 2π/h, these are the respective phases of the two waves. So as time t increases, x must increase at a rate of (E2 – E1)/(p2 – p1) to keep the phases equal. Now, since E2–p2=m2 for both waves, we have:
| (E2)2 – (p2)2 | = | (E1)2 – (p1)2 | |
| (E2)2 – (E1)2 | = | (p2)2 – (p1)2 | |
| (E2–E1)(E2+E1) | = | (p2–p1)(p2+p1) | |
| (E2–E1)/(p2–p1) | = | (p2+p1)/(E2+E1) |
The right hand side of the last line here is just the value of p/E for an “average” wave. Using the formulas we derived in the previous article, p=mv/√(1–v2) and E=m/√(1–v2), p/E is simply equal to the particle’s velocity v. So the velocity of a wave packet, the group velocity for de Broglie’s matter waves, matches the particle’s velocity.
In most experiments, particles like electrons can be localised to some degree: even when you can’t pin them down to the nearest nanometre, you know that they’re inside your apparatus and not on the other side of the planet. This suggests that they should generally be described by wave packets, which involve a localised “bump” in ψ, rather than a sine wave that goes on forever. But we’ve seen that the process of creating that bump means adding together waves that have a range of different momenta. To localise the particle, to give it anything like a definite position, we’ve had to give up the idea that it has a single, precise momentum.
This is just one manifestation of a famous aspect of quantum mechanics known as the uncertainty principle. It’s a simple mathematical fact about wave packets that the more sharply defined they are, the greater the range of wavelengths needed to build them – and that’s just as true for sound waves and water waves as it is for waves in quantum mechanics. Since wavelength equates to momentum for a de Broglie matter wave, the more sharply defined a particle’s position, the less well-defined its momentum will be.
The particle is localised where there’s a bump in ψ, but what about all the peaks and troughs in Figure 5, on which the bump is superimposed? Interference experiments with electrons can produce results exactly like those with light shown in Figure 1, so the variation in phase suggested by these peaks and troughs seems undeniable. But it turns out that it’s only the difference in phase between two split halves of an electron beam that can be detected – no experiment has ever measured peaks and troughs in an individual beam. Every water wave or sound wave produces a detectable rise and fall in water height or air pressure, so why should matter waves be different? How can they have a phase that shows up in interference experiments, but not in the wave itself?
It seems we were wrong to assume that matter waves take the form of sine waves. This doesn’t invalidate any of our results – which have all been based merely on the cyclic nature of the wave, not its exact value – but somehow, matter waves must be cyclic without growing weaker and stronger. That sounds paradoxical, but a vector can change direction cyclically without changing strength, and rotating vectors can certainly produce interference effects by pointing in different directions. Some matter waves are in fact vectors, but the simplest possible values for ψ are numbers that possess a kind of “internal” direction that has nothing to do with directions in spacetime. They’re known as complex numbers.
Complex Numbers
Several times in the history of arithmetic, people have stumbled upon the fact that they’d left out a useful class of numbers that obeyed all the same rules as the numbers with which they were already familiar. Negative numbers, fractions, and irrational numbers can all be manipulated by the same kind of operations as the natural numbers (0, 1, 2, 3...). If I tell you that x–6 = y–7, you don’t need to stop and wonder what kind of numbers x and y are, before you conclude that x = y–1. It makes no difference; the rules of algebra don’t discriminate.
The real numbers – which consist of all integers, all fractions, and all irrational numbers – seem to be about as complete as you could hope for: there are no gaps left to fill between them. However, the fact remains that if you assume that there’s a number, i, such that i2=–1, you can subject it to all kinds of algebraic manipulation without ever coming to grief. (Compare this with the assumption that there’s a number j such that 0 × j=1. Multiply by two, and you get 0 × j=2. Subtract the first equation from the second and you’ve proved that 0=1. That’s grief.)
The ordinary rules of algebra – if you leave out notions of order, such as always being able to classify y as less than x, greater than x, or equal to x — don’t discriminate against i any more than they discriminate against π or √2, and including i both enriches and simplifies almost every field of mathematics. Real multiples of i, such as 3i or –6.2i, are known as imaginary numbers. Sums of real and imaginary numbers, such as 1+4i or 2–√2i, are known as complex numbers.
Just as the number line is a useful way to visualise the set of real numbers, the complex plane provides the perfect equivalent for complex numbers. If you think of the real numbers as having a direction – the positive numbers pointing right and the negative numbers pointing left – then multiplying any number by –1 changes its direction by 180°, without changing its size. This metaphor can be extended by letting multiplication by i change the direction of any number by 90°, again without changing its size. This means i itself, being equal to i times 1, will lie at 90° from 1, and all the imaginary numbers will form a line perpendicular to the real number line. Complex numbers can then be visualised as points whose x and y coordinates are equal to their real and imaginary parts.
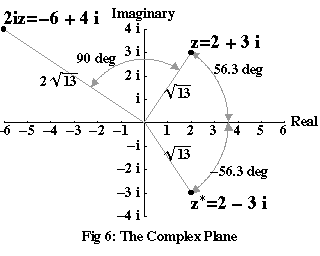
Figure 6 shows part of the complex plane, with the point representing a complex number z=2+3i marked on the diagram. To introduce some convenient notation, the real and imaginary parts of z, in this case 2 and 3i, are usually written Re z and Im z. The distance of z from 0, which is √(22+32)=√(13), is known as the magnitude of z, and is written |z|. The angle from the real line to z, in this case 56.3°, is known as the argument of z, and is written arg z.
Why should we care about these angles and distances? It turns out that the metaphor we used to construct the diagram, where we treated multiplication by –1 or i as a kind of rotation, works seamlessly for all complex numbers, so long as you also take into account their magnitude. Multiplying any two complex numbers w and z produces a result, wz, whose magnitude is |w||z|, and whose argument is arg z + arg w. In other words, multiplying z by w “stretches” z by a factor of |w|, and rotates it by an angle of arg w. For example, in Figure 6, the product of 2i and z has a magnitude of 2√(13) – which is |2i| times that of z – and it is rotated arg 2i, or 90°, away from z itself.
The number z*, also marked on the diagram, is known as the complex conjugate of z. It has the same real part as z, but its imaginary part is –Im z. Similarly, it has the same magnitude as z, but its argument is –arg z. Because of this, z*z must be a real number, since the sum of the two arguments comes to zero, and its magnitude must be |z*||z|=|z|2. If you check, (2–3i)(2+3i) = 4–6i+6i–9i2 = 13, or |z|2.
To describe a cyclic de Broglie wave that never changes size, we could use the complex number whose argument is equal to the phase of the wave, 2π(px – Et)/h:
| ψ(x,t) | = | cos(2π(px – Et)/h) + i sin(2π(px – Et)/h) | (7) |
This wave always has a magnitude of 1, but it moves in a circle around the complex plane, from 1 to i to –1 to –i and back to 1 again. Such a wave can exhibit constructive and destructive interference: if you split it into two beams, then recombine the beams with their phase unchanged, you’ll recover the original wave with a magnitude of 1; however, if you cause one beam to be precisely half a cycle out of phase with the other, the two waves will have opposite values when they meet (e.g. if one is i, the other will be –i), and they’ll add up to zero. Other phase differences will produce results in between those two extremes.
There’s a more concise way to write Equation (7), but it requires a brief mathematical detour. Most readers will be familiar with the concept of exponential growth: there are many systems, from populations of bacteria to bank deposits earning compound interest, that grow at a rate proportional to their own size. In most real situations the growth occurs in finite steps, but it’s possible to imagine an idealised case where growth is continuous. For example, a bank deposit earning 10% “nominal” interest might be multiplied daily by a factor of (1+0.1/365), where the annual rate has been converted to a daily one; over a year, this comes to (1+0.1/365)365 = 1.105155782, which is a little more than 10%. But there’s no reason why the bank’s computers couldn’t multiply the deposit hourly by (1+0.1/(365×24)), yielding (1+0.1/(365×24))365×24 = 1.105170287, a tiny bit more. If you imagine multiplying by (1+0.1/n), n times a year, for ever greater values of n – the number of minutes in a year, then seconds, then microseconds – with a smaller amount of growth at each individual step, but a greater number of steps, the result will approach the mathematical ideal of continuous exponential growth. It can be shown that after one year, the original deposit will have grown by a factor of exp(0.1), where exp is the exponential function:
| exp(x) | = | ex | (8) |
The number e, which has the value 2.71828..., is the factor by which a bank deposit would grow in one year if it earned 100% annual compound interest, calculated continuously. The factor for 10% continuous growth, e0.1 = 1.105170918, isn’t much different from our hourly calculation.
What’s all this got to do with cyclic complex waves, which don’t change size at all? If you perform the same kind of calculations with an imaginary “growth rate,” then at each stage you’ll be multiplying by a factor that rotates the previous number, rather than increasing it.
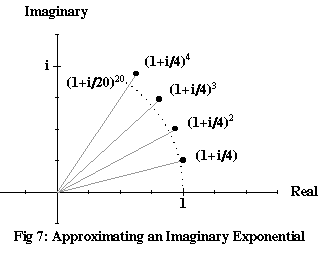
In Figure 7, we’ve plotted successive powers of 1+i/4, to show how they curve around into something that’s almost an arc of a circle. The reason they don’t quite form an arc is that the magnitude of 1+i/4 is more than 1, so each multiplication stretches as well as rotates the previous number. The series of smaller dots are the first twenty powers of 1+i/20; these do considerably better. The limit approached by (1+iθ/n)n as n gets ever larger – which we’ll call exp(iθ), since it’s really the very same exponential function as we applied to real numbers – is the complex number with a magnitude of 1 and an argument of θ (in radians, not degrees):
| exp(iθ) | = | cos θ + i sin θ | (9) |
In Figure 7, the dots are approaching exp(i), a number with a magnitude of 1 and an argument of 1 radian (about 57°).
The exponential function lets us write “cos + i sin” more concisely, but it has other advantages. How fast is your idealised 10% compound interest bank deposit growing, at the moment when you happen to have $1,000 in the account? At 10% of $1,000, or $100/year. The rate of change with time, t, of the exponential function exp(rt) is r exp(rt), the growth rate multiplied by the current value. Exponentials with imaginary growth rates are no different: the rate of change of exp(iθ) with θ, which we’ll write as ∂θ(exp(iθ)), is just:
| ∂θ(exp(iθ)) | = | i exp(iθ) | |
| = | –sin θ + i cos θ |
This makes sense: i exp(iθ) is the complex number that’s 90° away from exp(iθ), and just like a vector in spacetime that changes direction but not length, the rate of change of a complex number that isn’t actually growing or shrinking must be perpendicular to the number itself.
If you feed the exponential function two values added together, the separate results are multiplied:
| exp(a+b) | = | exp(a) exp(b) |
Why? This is really just saying (for example) that a bank deposit with a constant interest rate grows, over 5 years, by an overall factor that equals the growth over 3 years multiplied by the growth over 2 years. But it also makes sense with imaginary values: since exp(iθ) is the complex number with an argument of θ and a magnitude of 1, multiplying exp(iθ) by exp(iφ) will simply add the arguments, to give exp(i(θ+φ)).
We can now rewrite Equation (7) as an exponential of an imaginary number, instead of separate real and imaginary cos and sine waves:
| ψ(x,t) | = | exp(2πi (px – Et)/h) | (10) |
The pictures of ψ in Figures 4 and 5 were incomplete: they only showed Im ψ, the imaginary part of ψ, rather than the entire complex quantity – hence the misleading peaks and troughs. We can redraw these diagrams more accurately by showing the magnitude of ψ, and indicating the phase with shading.
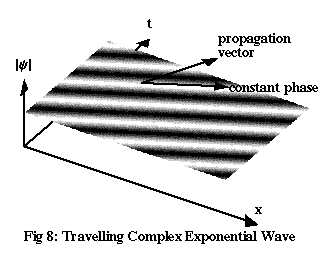

Since the phase of the wave is not directly detectable, if you alter it by a fixed amount – for example, by multiplying ψ throughout by a factor of i, adding 90° to the phase everywhere – all of its measurable properties will be unchanged. In effect, you can rotate the real and imaginary axes on the complex plane by any amount you like, changing the argument of ψ and its individual real and imaginary parts. Like choosing different spacetime coordinates, this has no effect on the actual physics.
How should we interpret the magnitude, |ψ|, of a wave that describes a single particle? Experiments show that the probability of finding the particle in a given region of space is proportional to the value of |ψ|2 times the volume of the region. The wave function only gives us a probability – it can’t tell us with certainty where the particle will be found. If quantum mechanics is correct, this is not a matter of lack of information, like our inability to predict the toss of a coin because we don’t happen to know the exact forces applied to it. Whenever the wave function spans a range of positions, the particle simply has no exact position.
What happens when an electron’s matter wave, spread out over several centimetres, hits a fluorescent screen and produces a tiny flash of light in just one (unpredictable) place? How does the particle suddenly “acquire” an exact position, if it didn’t have one all along? Broadly speaking, there are two schools of thought on this. One interpretation is that the original wave collapses into a narrower wave, a far more localised one, by some unspecified process that involves its interaction with the screen (or any other macroscopic object). The other interpretation is that, since the electron’s broad wave packet could be viewed all along as the sum of many narrower ones, a completely quantum mechanical treatment of the situation would show that the wave function for the screen could also be viewed as a sum of many parts, each describing a flash of light occurring in a different place. Likewise, the total wave function for a person who looked at the screen would be a sum of waves describing that person seeing the flash of light in various positions. This is known as the many worlds, or many histories, interpretation.
Why the square, in |ψ|2? Classical physics is full of examples of waves where the energy density is proportional to the square of the wave’s amplitude. If the probability density of a de Broglie wave is proportional to |ψ|2, the same mathematics that guarantees conservation of energy for classical waves works just as well to guarantee conservation of probability, so that if the chance of finding the particle somewhere in all of space is exactly 1 at a certain time, as it must be, this will continue to be true at later times.
If you doubled ψ everywhere, there’d still have to be the same total probability of 1 for finding the particle somewhere, so it’s the relative size of |ψ|2 from place to place compared to the total of |ψ|2 for all of space that matters. Because of this, it’s standard practice to normalise wave functions, dividing through by the total so that |ψ|2 itself is the probability density, rather than just being proportional to it. This is easy with a nice localised wave packet, such as the one in Figure 9, but even for idealised waves like the one in Figure 8, there are various mathematical tricks for dealing with the fact that the total of |ψ|2 is infinite, and the probability of finding the particle in any finite region is zero.
Wave Mechanics
It’s possible to construct every conceivable de Broglie wave for a “free particle” – a particle subject to no forces – by adding together various combinations of complex exponentials, exp(2πi (px – Et)/h), for different energies and momenta. This strategy can also be extended to include all three dimensions of space: we just use exp(2πi (pxx + pyy + pzz – Et)/h), with different values of px, py and pz setting the direction as well as the size of the momentum vector. The wavefronts of this exponential appear in three-dimensional space as a series of parallel planes, all perpendicular to the momentum vector, so ψ in this case is called a plane wave.
This all works very nicely, but to gain more insight into the de Broglie wave it would be helpful to have an equation for ψ, a concise mathematical statement of what constitutes a valid wave function, whether it’s a single plane wave with a definite momentum or the sum of a multitude of such waves.
How can we find such an equation? The energy and momentum of a particle satisfy the equation E2–p2=m2, so maybe we can construct something analogous for waves. If ψ=exp(2πi (px – Et)/h), the rates of change of ψ in space and time are:
| ∂xψ | = | 2πip/h ψ | |
| ∂tψ | = | –2πiE/h ψ |
where we’ve used the fact that the rate of change of any exponential is equal to its value multiplied by its “growth rate,” even when that rate is an imaginary number. If we divide by ±2πi/h, this gives:
| –(ih/2π) ∂xψ | = | pψ | (11a) |
| (ih/2π) ∂tψ | = | Eψ | (11b) |
where the minus sign appears in the first equation now, not the second, because 1/i is –i. These equations state that performing the operation on the left hand side – taking the rate of change of the wave function in either time or space, then multiplying by ±(ih/2π) – is exactly the same as simply multiplying the wave function by the energy or momentum. Repeating the process, taking the second rate of change and multiplying again by ±(ih/2π):
| –(h/2π)2 ∂x(∂xψ) | = | p2ψ | |
| –(h/2π)2 ∂t(∂tψ) | = | E2ψ |
To be more concise, we’ll write the second rates of change as ∂x2 and ∂t2; this doesn’t mean taking the rate of change then squaring it, but taking the rate of change of the rate of the change, as in calculating velocity from changing distance, then acceleration from changing velocity. (The most widely used notation is “∂ψ/∂x” and “∂2ψ/∂x2,” but we’ll stick to the more compact form.)
The energy and momentum of the particle satisfy E2–p2=m2. If we multipy this equation by the value of the wave function ψ, then substitute the results we’ve just found for p2ψ and E2ψ:
| m2ψ | = | E2ψ – p2ψ | |
| m2ψ | = | –(h/2π)2 ∂t2ψ + (h/2π)2 ∂x2ψ | |
| (2πm/h)2 ψ | = | ∂x2ψ – ∂t2ψ |
or, to include all three dimensions of space:
| (2πm/h)2 ψ | = | ∂x2ψ + ∂y2ψ + ∂z2ψ – ∂t2ψ | (12) |
We assumed originally that ψ was a complex exponential wave with a definite energy and momentum, but this is a linear equation: if you have two different waves, ψ1 and ψ2, that satisfy Equation (12), then a linear combination of the two, Aψ1 + Bψ2, will also satisfy it, for any values of A and B. This means that any de Broglie wave that we build up from any number of plane waves must satisfy it too.
Equation (12) is known as the Klein-Gordon equation, or the relativistic Schrödinger equation. Erwin Schrödinger came up with it first, but Klein and Gordon derived it independently, and published it before him. The equation for which Schrödinger is more famous is a non-relativistic version, which he obtained by using the relationship E=p2/2m from Newtonian physics (that’s just K=mv2/2, with v rewritten as p/m) and taking the same approach as we’ve followed to turn this into a wave equation:
| (ih/2π) ∂tψ | = | –(h/2π)2/2m (∂x2ψ + ∂y2ψ + ∂z2ψ) | (13) |
Equation (13) is the Schrödinger equation for a free particle. Like Equation (12), it has solutions of the form exp(2πi (px – Et)/h), though in this case p and E are the classical momentum and energy, p=mv and E=K=mv2/2, not the relativistic values. But Schrödinger’s great success was in adapting this equation for a particle subject to forces, such as the electrostatic force between an atom’s positively charged nucleus and its electrons. In Newtonian physics, forces are often described via a potential energy, V(x), that depends on the particle’s position in space. For example, an electron must have more potential energy the further it is from the nucleus, because like a ball rolling downhill it will speed up when it’s drawn closer, converting that potential energy into kinetic energy. The particle’s total energy, kinetic plus potential, then satisfies the equation E=p2/2m+V(x), and the equivalent wave equation is:
| (ih/2π) ∂tψ | = | –(h/2π)2/2m (∂x2ψ + ∂y2ψ + ∂z2ψ) + V(x)ψ | (14) |
Equation (14) was used by Schrödinger to explain the mysterious energy levels that Bohr had postulated for the hydrogen atom. Unlike the wave for a free particle, the wave for an electron in an atom can’t take on any shape it likes: it’s constrained by the geometry of the situation to “fit” an exact number of cycles around the nucleus. Other people had suggested something similar, but their models resembled the vibrations in a circular string with a sharply defined distance from the nucleus, an exact “orbit.” Schrödinger’s solutions to Equation (14), known as orbitals, are spread out across a range of distances rather than specifying the electron’s position precisely.
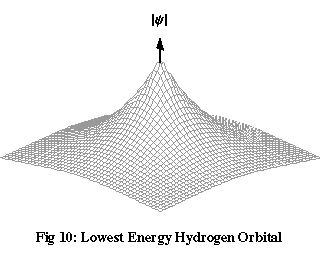

Figures 10 and 11 show two solutions to Schrödinger’s equation for a hydrogen atom. These are graphs of the value of |ψ| on a plane passing through the nucleus of the atom, at a single moment of time. The only variation of ψ with time is a cycling of the overall phase, which has no effect on the electron’s probability density, so these are described as stationary wave functions.
The orbital with the lowest energy, shown in Figure 10, is completely spherically symmetrical: there’s an equal chance of finding the electron in any direction relative to the nucleus, though it’s more likely to be found closer to the nucleus than further away. The second orbital, not shown, is identical in shape, but the electron is, on average, further from the nucleus. The third orbital, shown in Figure 11, localises the electron into two lobes with opposite phase on either side of the nucleus. If you take the areas of the plane where |ψ| has a significant value and imagine spinning them around an axis joining the lobes, you’ll see that the shape of the three-dimensional region where the electron is most likely to be found is a kind of dumb-bell.
Although Schrödinger’s equation only gives an approximate treatment of an electron in an atom – it doesn’t deal with relativistic effects, and it neglects an important property of electrons, their “spin” – a vast amount of the behaviour of atoms and molecules can be explained with it. Most of the differences between chemical elements and the regularities in the periodic table can be accounted for by the way elements with increasing atomic number – the number of protons in the nucleus, which is matched by an equal number of electrons – fill up more and more orbitals, creating a predictable pattern in the kind of chemical bonds that the outermost electrons can form.
The wave function for a system of two particles, such as the two electrons in a helium atom, is not the sum of two single-particle wave functions. Rather, it’s a function ψ(x1,y1,z1,x2,y2,z2,t) that depends on the spatial coordinates of both particles, and which satisfies a 6-spatial-dimensional version of Schrödinger’s equation:
| (ih/2π) ∂tψ | = | –(h/2π)2/2m1 (∂x12ψ + ∂y12ψ + ∂z12ψ) | |
| –(h/2π)2/2m2 (∂x22ψ + ∂y22ψ + ∂z22ψ) + V(x1,x2)ψ |
This means, unfortunately, that we can’t really imagine the universe in quantum mechanical terms as being a three dimensional place that’s merely full of wave functions, rather than the particles of classical physics. That picture works for a single particle, but the waves of different particles can neither be added together when they’re in the same place – which is how classical waves, like those in the electromagnetic field, behave – nor do they generally pass right through each other without any effect. It takes a single wave in six-dimensional space to describe two particles, and one in 3N-dimensional space to describe N particles.
That said, we often do want to consider the behaviour of a single particle, putting everything else in the universe aside (or treating it with classical physics). So the image of a wave in ordinary space can still provide a useful intuitive picture, so long as you never forget that you’re really just looking at a three-dimensional slice of something far more complex.
Matrix Mechanics
In the 1920s and ’30s, in parallel with Schrödinger’s wave mechanics, Werner Heisenberg developed a very different approach to the same problems, known as matrix mechanics. Though Schrödinger eventually proved that the two theories were mathematically equivalent, and though wave mechanics had the initial advantage of offering something relatively concrete to visualise – at least in the case of single-particle wave functions – Heisenberg’s approach has turned out in the long run to be the most flexible and coherent way to understand quantum mechanics.
In matrix mechanics, every quantum mechanical system is treated as a vector space. Everyone’s familiar with at least one example of a vector space: in three-dimensional Newtonian physics, all the possible velocities a particle might have – all the different directions and speeds with which it might be moving – comprise a three-dimensional vector space. You can add and subtract vectors (e.g. the velocity 30 km/h north plus the velocity 40 km/h east gives a velocity of √(302+402)=50 km/h north-east) or multiply them by ordinary numbers to create longer or shorter vectors pointing in the same direction (e.g. 5 times the velocity 2 metres/sec upwards is the velocity 10 metres/sec upwards).
Vector spaces with more than three dimensions are harder to visualise, but there’s really no need to be able to do that. The mathematics itself generalises to any number of dimensions very easily, and you can understand most things about a 10-dimensional vector space just by picturing the three-dimensional version, but using the 10-dimensional equations.
To give an example of this, one additional feature that Heisenberg needed for his quantum mechanical vector spaces is a formula called an inner product, which is very similar to the Euclidean metric we introduced back in the article on special relativity. The inner product of two vectors, v and w, is a number, written as <v,w>, that depends on the size of both vectors and their relative directions. The length of any vector is given by |v|2=<v,v>, and two vectors are considered to be perpendicular, or “orthogonal,” if <v,w>=0. For real vector spaces (in contrast to complex ones, which we’ll come to shortly), the inner product is completely linear and symmetric:
| <av+bw,u> | = | a<v,u>+b<w,u> |
| <v,au+bw> | = | a<v,u>+b<v,w> |
| <v,w> | = | <w,v> |
Now, suppose we’re dealing with a 10-dimensional vector space, in which we’ve picked 10 mutually orthogonal vectors, e1, e2, e3, ... e10. Don’t panic, you don’t need to visualise anything more than the first three of these, which are just like the x-, y- and z-axes of Euclidean space. What’s more, suppose that |ej|=1 for j=1,2,...,10, i.e. they’re all unit vectors, vectors with a length of 1. A set of mutually orthogonal unit vectors is known as an orthonormal basis, and like the coordinate vectors we used for velocities in relativity, any vector can be written as a sum of multiples of these vectors.
Suppose that v=v1e1+...+v10e10 and w=w1e1+...+w10e10, and we’re dealing with a real vector space. Since the inner product is linear, we have:
| <v,w> | = | v1w1+v2w2+v3w3+...v10w10 | (15) |
where out of all the one hundred terms that you’d get if you expanded the left-hand side in full, such as v4w5<e4,e5>, this is all that remains, because <e4,e5> etc. are zero (the ej being mutually orthogonal), and <e1,e1> etc. are all exactly 1 (the ej being unit vectors). Equation (15) is an obvious extension to 10 dimensions of the three-dimensional Euclidean metric, g(v,w)=vxwx+vywy+vzwz, and so the inner product here behaves in essentially the same way as that metric. For example, the length of the projection of v in the direction of w is just <v,w>/|w|, which is just like the formula for the same thing in three-dimensional Euclidean space, g(v,w)/|w|.
To illustrate the link with wave mechanics, we’re going to use a “toy universe,” a highly simplified model of reality that nonetheless exhibits most of the important features of quantum mechanics. Imagine a 1-dimensional universe, with only three possible positions a particle can occupy, forming a ring: x=0, 1, 2. Assume that there is no time. Figure 12 shows a wave function in space that undergoes one cycle of phase as it wraps around the entire “universe.” The different shades here represent three different phases, separated by 120° or 2π/3: exp(2πi x/3) for x=0, 1 and 2. To normalise this function – to make the total of |ψ|2 equal to 1 – we divide these three values by √3.
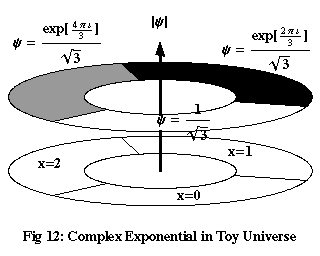
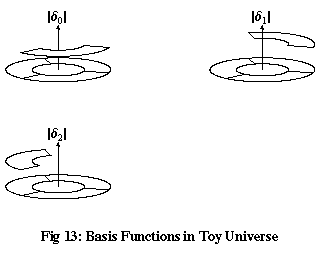
Now, consider the three functions in Figure 13, δ0, δ1 and δ2, which are equal to 1 when x is equal to 0, 1 and 2 respectively, and equal to zero for all other values of x. We can express any function of x in our toy universe as a sum of multiples of δ0, δ1 and δ2. For example, to take the function ψ in Figure 12:
| ψ | = | ψ(0) δ0 + ψ(1) δ1 + ψ(2) δ2 | |
| = | (1/√3) δ0 + (exp(2πi/3)/√3) δ1 + (exp(4πi/3)/√3) δ2 |
What has this got to do with vector spaces? By writing a function in terms of these δ functions, it can be thought of as a vector in a three-dimensional vector space, where the three δ functions are orthonormal basis vectors, and the values of the function ψ at x=0, 1 and 2 are the coordinates of the corresponding vector.

Since we need to be able to talk about complex functions like ψ, this is a complex vector space. All that really means is: instead of only being allowed to multiply vectors by real numbers, it’s permitted to multiply them by complex numbers, and any vector might have complex numbers as its coordinates when it’s written out in terms of some basis. We don’t have enough dimensions to visualise this completely – each complex dimension really needs a two-dimensional plane, making a total of six dimensions – but if we use distances equal to the magnitude of each complex coordinate on a three-dimensional diagram, we can get a reasonable idea of what’s going on, so long as we don’t forget that each of these coordinates is really a complex number with an argument, or phase, as well as a magnitude. (To separate out different points whose coordinates all have the same magnitude, we’ll also use the completely arbitrary convention that any coordinate with a negative imaginary part will be drawn on the negative side of the axis.)
There’s one small adjustment that we need to make in order to deal properly with complex vectors. If the length of a vector is to be a real number, and |v|2=<v,v> is still to be true, then we need to ensure somehow that <v,v> will be a positive real number. We’d also like the idea of the length of a vector to be compatible with the idea of the magnitude of a complex number, in the 1-dimensional case where the vector space is just the set of complex numbers themselves. We can change the definition of the inner product in a way that solves both these problems, simply by requiring that instead of being linear in its first “slot,” the inner product is “conjugate linear”:
| <av+bw,u> | = | a*<v,u>+b*<w,u> | |
| <v,au+bw> | = | a<v,u>+b<v,w> | |
| <v,w> | = | <w,v>* |
Note that the second slot is still just plain linear. When the numbers a and b and the inner product are all real, taking the conjugate leaves them unchanged, so these new definitions don’t alter anything in the case of real vector spaces. For a complex vector space, if you write out two vectors v and w in terms of an orthonormal basis, you now get:
| <v,w> | = | (v1)*w1+(v2)*w2+(v3)*w3+... | (16) |
In the 1-dimensional case, if a vector is v=z1e1, then |v|2=<v,v>=(z1)*z1=|z1|2 (the product of any complex number and its conjugate is just its magnitude squared) making the length of v equal to the magnitude of its single complex coordinate. And in N dimensions, |v|2 will be equal to the sum of the squares of the magnitudes of all its coordinates, which is the kind of nice Pythagorean result you’d expect.
A complex vector space for which an inner product has been defined is known as a Hilbert space, and this definition of the inner product allows us to write many things about the wave function very simply, when it’s treated as a vector in a Hilbert space. The normalisation condition – the sum of all the probabilities of finding the particle in different locations being equal to 1 – becomes simply:
| 1 | = | |ψ(0)|2+|ψ(1)|2+|ψ(2)|2 | |
| = | ψ(0)*ψ(0)+ψ(1)*ψ(1)+ψ(2)*ψ(2) | ||
| = | <ψ,ψ> | ||
| = | |ψ|2 | (17) |
So a wave function being normalised simply means it has a vector of length 1, and in matrix mechanics, it’s the vectors of length 1 that correspond to possible states of the system, or state vectors.
We can also use the inner product to identify individual probabilities. The probability of finding the particle at the position x=1, say, is |ψ(1)|2. But:
| <ψ,δ1> | = | <ψ(0) δ0 + ψ(1) δ1 + ψ(2) δ2, δ1> | |
| = | ψ(0) <δ0, δ1> + ψ(1) <δ1, δ1> + ψ(2) <δ2, δ1> | ||
| = | ψ(1) |
since the δ vectors are orthonormal. So the probability |ψ(1)|2 can also be written as |<ψ,δ1>|2. That might not seem like much of an advance, but we’ve now gone from evaluating the wave function ψ at a certain point, to projecting the state vector ψ onto another state vector, δ1, to discover the probability that the system will “pass a test” for being in the state δ1: namely, checking to see if the particle can be found at x=1.
It turns out that this works in general. If you have some kind of test that you know will always be passed if you arrange for your quantum system to have a state vector of φ, but instead you prepare it with a different state vector, ψ, then the probability that it will pass the test anyway is given by |<ψ,φ>|2. Since the lengths of both vectors are 1, what |<ψ,φ>| represents is the angle between them: it will be zero if the two are perpendicular, 1 if they’re parallel, and something in between if they’re neither parallel nor perpendicular. For example, if you prepare a particle in the state δ2, where you know it’s located at x=2, then it will certainly fail a test for being at x=1. On the other hand, a particle in the state (δ1+δ2)/√2 will have a chance of |<(δ1+δ2)/√2,δ1>|2=1/2 of being found at x=1, and also a chance of |<(δ1+δ2)/√2,δ2>|2=1/2 of being found at x=2.
Being able to write the probabilities of obtaining various measurements this way allows us to calculate the average, or mean, value of a measurement. For example, suppose we prepare a particle in our toy universe in the state ψ, and then measure its position, x. If we repeat the whole procedure many times, the average value we’d expect from all the measurements of x is just the sum of the possible values multiplied by the respective probabilities of obtaining them:
| mean(x) | = | 0 |<ψ,δ0>|2 + 1 |<ψ,δ1>|2 + 2 |<ψ,δ2>|2 |
We can rewrite this more concisely by constructing a handy mathematical “package” for the whole business of taking a measurement of x, making use of the fact that measuring position involves the projection of the state vector onto the various δ vectors. We define a tensor X:
| X | = | 0 δ0⊗δ0 + 1 δ1⊗δ1 + 2 δ2⊗δ2 | (18) |
where the tensor product ⊗ means that v⊗w(u)=<w,u>v. In other words, we can “feed” any tensor v⊗w a single vector, u, to combine with w, leaving v to be multiplied by the inner product <w,u>. Then:
| <ψ,X(ψ)> | = | <ψ, 0 δ0⊗δ0(ψ) + 1 δ1⊗δ1(ψ) + 2 δ2⊗δ2(ψ)> | |
| = | <ψ, 0 <δ0,ψ>δ0 + 1 <δ1,ψ>δ1 + 2 <δ2,ψ>δ2> | ||
| = | 0<δ0,ψ><ψ,δ0>+1<δ0,ψ><ψ,δ0>+2<δ0,ψ><ψ,δ0> | ||
| = | 0 |<ψ,δ0>|2 + 1 |<ψ,δ1>|2 + 2 |<ψ,δ2>|2 | ||
| = | mean(x) | (19) |
This tensor X is known as the position matrix. Why “matrix”? We could write a square matrix of all the tensor coordinates of X, all the numbers by which each of the δi⊗δj are multiplied. This would have 0, 1 and 2 along its diagonal, and zeroes everywhere else. For people familiar with matrix algebra this can be very useful, but we won’t pursue that approach. A matrix or tensor like this, constructed for some quantity that you can measure for a system, is known as an observable.
It’s easy to see from the definition of X that:
| X(δ0) | = | 0 δ0 | (20a) |
| X(δ1) | = | 1 δ1 | (20b) |
| X(δ2) | = | 2 δ2 | (20c) |
Here, we’re writing things like 0 δ0 and 1 δ1 in full – rather than just 0 and δ1, which is what they come to – to emphasise the pattern. Feeding a vector with a definite value of position, x, to the position matrix, X, just multiplies that vector by the value of x. This is summed up by saying that δ0, δ1 and δ2 are eigenvectors of X, with eigenvalues of 0, 1 and 2 respectively. In general, X(φ) for some state vector φ won’t be a multiple of φ; this will only be true if φ is parallel to one of the δ vectors.
When we were working out the wave equations by taking the rates of change of a complex exponential ψ=exp(2πi (px – Et)/h), we found that:
| –(ih/2π) ∂xψ | = | pψ |
This is saying something very similar to Equations (20)! The operation on the left hand side generally takes one function and produces another very different one, but in the special case where ψ is a complex exponential, it simply multiplies ψ by p, the value of the momentum. In wave mechanics, ψ is called an eigenfunction of the momentum operator –(ih/2π) ∂x, with eigenvalue p.
Can we come up with a momentum matrix for our toy universe, a tensor whose eigenvectors have definite values of momentum? How do we compute the rate of change with a tensor? We can use projection onto the δ vectors to extract the value of the wave function at the two positions on either side of each location — recalling that <ψ,δ1>=ψ(1), etc. – and take the difference. The tensor to do this is:
| D | = | δ0⊗(δ1–δ2) + δ1⊗(δ2–δ0) + δ2⊗(δ0–δ1) | (21) |
In wave function terms, the result that D produces at each location x=0, 1 and 2 is the difference between the values of the wave at the locations on either side. In vector terms, the components D produces in the δ0, δ1 and δ2 directions are the difference between the other two components of the vector. (The actual rate of change per unit distance will be half this, since the two values of x are separated by a distance of 2, but we’ll put in that factor later.)
We can test this on the complex exponential ψ shown in Figure 12, but first we’d better write out ψ explicitly in real and imaginary parts, using Equation (9), exp(iθ)=cos(θ)+isin(θ), and a few facts that you can find in any trigonometry book: sin(2π/3)=√3/2, sin(4π/3)=–√3/2, and cos(2π/3)=cos(4π/3)=–1/2.
| ψ | = | (1/√3) δ0 + (exp(2πi/3)/√3) δ1 + (exp(4πi/3)/√3) δ2 | |
| = | (1/√3) (δ0 + (–1+√3i)/2 δ1 + (–1–√3i)/2 δ2) | ||
| D(ψ) | = | (1/√3) (√3i δ0 + (–√3i–3)/2 δ1 + (–√3i+3)/2 δ2) | |
| = | √3i ψ |
So ψ is, as we’d hoped, an eigenvector of the “rate of change” matrix D, with eigenvalue √3i. If we define the momentum matrix, P, as P=–(ih/2π)(1/2)D, then:
| P(ψ) | = | –(ih/2π)(1/2)D(ψ) | |
| = | –(ih/2π)(1/2)√3i ψ | ||
| = | (h√3/4π) ψ |
The wave ψ has a wavelength of 3, so the de Broglie relationship in Equation (3) suggests that the momentum should be h/3, but we can’t expect to get exactly the same numerical result in our toy universe, where space is discrete on such a coarse scale.
Since this state vector is a momentum eigenvector with one positive “unit” of momentum – h√3/4π seems to be a quantum of momentum in our toy universe – we’ll rename it p1. And it’s easy to find another eigenvector of D; since D itself involves no complex numbers, taking the complex conjugate of the whole equation D(p1)=√3i p1 yields D(p1*)=–√3i p1* (where we’ve used the fact that the complex conjugate of two things multiplied together – in this case √3i and p1 – is just the product of their individual complex conjugates). So we immediately have a second eigenvector:
| p–1 | = | p1* | |
| = | (1/√3) (δ0 + (–1–√3i)/2 δ1 + (–1+√3i)/2 δ2) | ||
| P(p–1) | = | (–h√3/4π) p–1 |
This eigenvector has one negative unit of momentum, so in a sense it’s the “time reverse” of p1. There’s also a third eigenvector, with a momentum of zero:
| p0 | = | (1/√3) (δ0 + δ1 + δ2) | |
| P(p0) | = | 0 p0 |
These three vectors are mutually perpendicular, <p0,p1>=0, <p0,p–1>=0, <p1,p–1>=0, so they form an orthonormal basis, just as the δ vectors do. Because the p basis consists of vectors whose coordinates in the δ basis all have equal magnitudes (of 1/√3, in this three-dimensional case), these two bases point in directions that “avoid each other” as much as possible. Such a pair of bases are known as complementary.
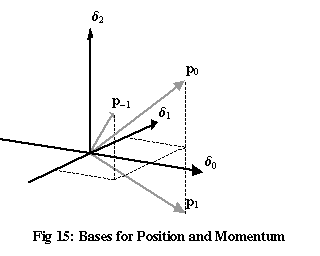
The p vectors in Figure 15 don’t look perpendicular. This isn’t the result of drawing the three-dimensional diagram in two dimensions – rather, it’s the result of drawing three complex dimensions as three real ones. In a real three-dimensional space, there’s no way to find three perpendicular vectors that all have equal-sized projections onto the x-, y– and z-axes. It’s only the fact that p0, p1 and p2 have the extra freedom of complex phases that allows them to be mutually perpendicular.
We can write the P matrix in terms of its own eigenvectors, to get a much simpler expression for it than the one based on D and Equation (21). Just like Equation (18) for X, we take all the possible values for the momentum, p, and multiply them by tensors that project onto the states with those values of momentum:
| P | = | (h√3/4π) (–1 p–1⊗p–1 + 0 p0⊗p0 + 1 p1⊗p1) | (22) |
As with X, this matrix allows us to calculate the average momentum for any state vector ψ, as <ψ,Pψ>. And as with the momentum operator for wave functions, this matrix can be used in matrix equations, similar to the Klein-Gordon and Schrödinger wave equations.
Because the real world has an infinite number of possible locations for particles (or at least, that’s the current simplest assumption), doing matrix mechanics usually means dealing with the subtleties of infinite-dimensional vector spaces. Most of the methods and general principles, though, are similar to those we’ve been using in the finite-dimensional case.
The Uncertainty Principle
The uncertainty principle is the inability of a quantum system to possess sharply defined values of certain pairs of variables, such as position and momentum. Unfortunately, this simple fact is sometimes shrouded in confusion, some of which probably dates back to a famous thought experiment of Heisenberg’s in the 1920s. Heisenberg pointed out that, because light comes in quanta with a minimum amount of energy and momentum for any given wavelength, even if an electron was a point particle straight out of classical physics, we could never illuminate one in order to see where it was without disturbing it to some degree in the process. This is a perfectly true statement – but it’s a true statement about a hypothetical alternative universe, because electrons aren’t classical point particles. A correct description of an electron, whether as a wave function in ordinary space or a state vector in a Hilbert space, shows that it doesn’t need to be “disturbed” by anything in order to be subject to the uncertainty principle. It simply can’t possess an exact momentum and an exact position at the same time, any more than a musical note can be a perfect middle C, giving it a well-defined frequency, while lasting for a billionth of a second, giving it a well-defined location in time.
The complementary bases for position and momentum shown in Figure 15 illustrate the true source of the uncertainty principle. For a quantum state to have a definite position, all but one of its δ coordinates would need to be zero. For a quantum state to have a definite momentum, all but one of its p coordinates would need to be zero. It’s obvious from Figure 15 that these two requirements can’t be satisfied by the same vector.
The uncertainty principle flows entirely from the geometry of the Hilbert space describing the quantum system. You could perform separate measurements on two thousand identically prepared quantum systems, measuring position in half of the experiments and momentum in the other half – there’d be no question, then, of position measurements in one experiment disturbing momentum measurements in another – and it would still be impossible for the measurements to show a sharply defined momentum without a correspondingly broad range of values for position, and vice versa.
Not all pairs of different quantities suffer from the uncertainty principle. If we extended our toy universe to give it three y positions for each x position, then there’d be no contradiction in a state vector having definite values of both x and y. We’ve run out of dimensions in Figure 15, but the extra freedom of the y position would require a total of nine complex dimensions in the system’s Hilbert space, with orthogonal vectors δ00, δ01, δ02, δ10 ... for (x,y)=(0,0), (0,1), (0,2), (1,0) etc. Each of these nine vectors would possess, simultaneously, exact values for both x and y, and they’d be eigenvectors of both X and Y. (The definition of X in Equation (18) would have to be expanded, of course, to cover this new set of possibilities.) However, not every state with a definite x would necessarily possess a definite y, or vice versa. For example, (δ10+δ12)/√2 would have a probability of 100% to be found at x=1, but a 50/50 chance of being found either at y=0 or y=2.
Suppose two observables A and B share N orthonormal eigenvectors, where N is the total dimension of the Hilbert space. (This is true for X and Y in the example we’ve just given.) Call those eigenvectors e1, e2, ... eN. They need not have identical eigenvalues for A and B, so suppose that the eigenvalues for A are μ1, μ2, ... μN and the eigenvalues for B are λ1, λ2, ... λN.
Now, we can write any vector v as v=v1e1+v2e2+...+vNeN, so we have:
| A(B(v)) | = | A(B(v1e1+v2e2+...+vNeN)) | |
| = | A(v1λ1e1+v2λ2e2+...+vNλNeN) | ||
| = | v1λ1μ1e1+v2λ2μ2e2+...+vNλNμNeN | ||
| = | B(v1μ1e1+v2μ2e2+...+vNμNeN) | ||
| = | B(A(v1e1+v2e2+...+vNeN)) | ||
| = | B(A(v)) |
Even though v as a whole isn’t an eigenvector of A or B, the fact that it can be expressed as a linear combination of vectors that are eigenvectors of both these observables means that the effects of A and B can be interchanged, or commuted, just like the effects of multiplying by a number. Because of this, it’s handy to define a matrix called the commutator of A and B, which is written as [A,B]:
| [A,B](v) | = | A(B(v)) – B(A(v)) | (23) |
Observables with a commutator of zero are precisely those that aren’t subject to the uncertainty principle. Like X and Y, the matrices E and P for energy and momentum commute, and there’s no contradiction between precision in a state’s energy and in its momentum. It’s possible to go further: it can be shown (with some technical caveats) that a statistical measure of the “spread” of two variables, their standard deviations, are related to the commutator for their observables. If the standard deviation of a variable is defined as:
| Δa | = | √(mean(a2)–(mean(a))2) | |
| = | √(<ψ,A2ψ>–<ψ,Aψ>2) |
then:
| Δa Δb | ≥ | (1/2)|<ψ, [A,B]ψ>| | (24) |
Unfortunately, P and X in our toy universe actually fail some of the technical requirements needed for this to be true (because x undergoes a sudden jump in value from 3 back to 0, which complicates things). But Inequality (24) can be applied just as well to operations on a wave function, such as multiplying it by x, or acting upon it with the momentum operator –(ih/2π) ∂x. With a little bit of calculus, we see that:
| [x, –(ih/2π) ∂x]ψ | = | –(ih/2π) x∂xψ + (ih/2π) ∂x(xψ) | |
| = | –(ih/2π) x∂xψ + (ih/2π) x∂xψ + (ih/2π) ψ | ||
| = | (ih/2π) ψ |
and so:
| Δx Δp | ≥ | (1/2)|<ψ, (ih/2π) ψ>| | |
| = | (h/4π) |<ψ, ψ>| | ||
| Δx Δp | ≥ | h/4π | (25) |
where we’ve used the fact that ψ is normalised, <ψ, ψ>=|ψ|2=1. Inequality (25) quantifies the extent to which a low value for the spread in x must be compensated for by a high value for the spread in p, in order that the product of the two never fall below h/4π.
To give an example, an electron with an uncertainty in its position of 10–10 m (about the diameter of a hydrogen atom) will have an uncertainty in its momentum of at least h/4π/10–10, or 5.3 × 10–25 kg m/sec. Dividing by its mass (9.1 × 10–31 kg), that means an uncertainty in its velocity of 580,000 m/sec (about 0.2% of lightspeed).
The Action Principle
We’ll conclude with a brief discussion of a third important way of looking at quantum mechanics. In the 17th century, Fermat discovered that the paths taken by light rays always involve less travel time than nearby alternatives. For example, the angle at which light bends when moving from air to glass (in which it travels at different speeds) allows it to get from A to B faster than if it had taken a straight line. The path need not involve an absolute minimum amount of time, though, just a “local” minimum: light going from A to B by bouncing off a mirror takes longer than light travelling a straight line from A to B — but bouncing at the same angle to the surface of the mirror when arriving and departing takes less time than reflection at any other angle, and that’s what light does.
Why does Fermat’s principle work? Because the bottom of a valley is flat. In other words, near a local minimum, a range of slightly different paths all involve almost the same travel time. Waves are always a bit spread out, they don’t travel along any single, precise path. But if they follow a set of paths where any slight variation has relatively little effect on the travel time — the flat bottom of a valley, as opposed to the steep slopes – the separate parts of the wave will still arrive almost in phase, and they’ll reinforce each other. Elsewhere, they’ll slip out of phase more rapidly, and cancel each other out.
In the 18th and 19th centuries, Lagrange and Hamilton extended this principle to the classical mechanics of material objects. If you define the Lagrangian, L, of a system to be its kinetic energy minus its potential energy, then for any possible motion of the system you can calculate a quantity called the action, S, by integrating (adding up) the value of the Lagrangian at successive moments. The actual motion always turns out to involve a stationary point of the action: on a graph it will always be the bottom of a valley, the top of a hill, a flat mountain pass, a plain.
Lagrange and Hamilton derived all their results from Newtonian mechanics, but with the advent of quantum mechanics the action principle made perfect sense. If matter is a wave too, it’s subject to the same effects as light. A matter wave can’t follow a perfectly narrow path, so it can only stay in phase by following a range of paths that involve more or less the same phase shift.
Applying this logic to the phase of a wave that satisfies Schrödinger’s equation leads back to the classical action, the integral of kinetic energy minus potential energy. Applying it to the phase of a wave that satisfies the Klein-Gordon equation leads to a relativistic action for a free particle that’s even simpler: S=mτ, the rest mass of the particle, m, multiplied by the proper time, τ, along its world line. That in turn explains the fact that particles travel along geodesics in spacetime – paths that involve a local maximum in proper time, just as geodesics in space involve a local minimum of distance. Because the “top of the mountain” is flat, geodesics offer wave packets their best opportunity for remaining in phase. The Earth orbits the sun because it’s following the world line through curved spacetime for which the wave packets of its individual atoms remain in phase.
That beautiful image serves as a reminder that a single set of physical principles must account for the behaviour of every kind of matter and energy, at every scale. But quantum mechanics has yet to be applied successfully, not merely to particles in curved spacetime, but to spacetime geometry itself. That’s going to be a task for the twenty-first century.
Further reading: A good introductory textbook for readers with some background in classical physics is Quantum Mechanics by Leonard I. Schiff (McGraw-Hill, 1968). Quantum Theory: Concepts and Methods by Asher Peres (Kluwer, 1993) provides a more modern treatment of “foundational” issues, as well as topics such as the interactions of quantum systems with measuring apparatus, and quantum chaos. QED: The Strange Theory of Light and Matter by Richard P. Feynman (Penguin, 1985) is a wonderfully lucid (and almost mathematics-free) account of the most advanced branch of quantum mechanics, quantum field theory.