
There was a discussion recently on John Baez’s Google Plus blog about a beautiful image, created by a mathematical artist going by the name TaffGoch, of 92 gears spinning on a sphere, with their centres arranged in a pattern with icosahedral symmetry. The question arose as to how this kind of thing might be generalised to higher dimensions. (A further discussion followed on the same blog.)
If we go from three dimensions to n dimensions, we need to replace the original sphere with Sn–1: the set of points an equal distance from the origin in Rn, and we will replace the circular gears with spheres one dimension lower, Sn–2. Rather than trying to create some higher-dimensional equivalent of gear teeth, we will simply allow these spheres to roll at their points of contact, like ball bearings.
Suppose we choose some set of unit vectors giving the centres of all the ball bearings, and we choose the radii of the ball bearings so that some pairs of them make contact. In any dimension, we can define the angular velocity of a rigid body as a matrix that takes a position vector s for some point on the body and turns it into the linear velocity v = ds/dt of that point due to the rotation. Because the motion is rigid, any s must have a rate of change that is orthogonal to s itself (otherwise s would be changing in length, deforming the body). It follows that if the angular velocity matrix is M, then s · (M s) must be zero for any s, which implies that M is an antisymmetric matrix.
As Allen Knutson pointed out in the original thread, we will have a system of linear equations that the angular velocities of the ball bearings must satisfy. Just as the rotation of each gear in the three-dimensional setup needs to leave the centre of the gear unchanged, the angular velocities of the ball bearings need to leave their centres unmoving. If the centres are ci and the angular velocities are Mi, we have the equations:
Mi ci = 0
If the point of tangency between ball bearings i and j is given by ti,j, we also need the linear velocities of each bearing at that point to agree. That is, the two spheres need to make rolling contact, rather than slipping past each other.
Mi ti,j = Mj ti,j
An antisymmetric n × n matrix has ½n(n–1) independent components (all those above the diagonal, say, and then all those below the diagonal are determined by the antisymmetry). So if we have b ball bearings altogether, the linear system will have ½n(n–1) b variables. If there are p points of contact, the total number of equations will be n (b + p), but as we will see some of these will turn out to be redundant.
At this point we will switch from the general situation and work through one concrete example. Suppose we set n=4, so the ball bearings are fixed within a 3-sphere, and each one’s surface is a 2-sphere. To choose a pattern for the ball bearing’s centres, we will start from the features of a 4-cube, or hypercube. A 4-cube has 16 vertices (or “0-faces”), 32 edges (or “1-faces”), 24 square faces (or “2-faces”), and 8 cubical faces (or “3-faces”). We will take the centres of all of these k-faces, project them onto the unit 3-sphere, and place a ball bearing at each such point.
This makes for a total of 80 ball bearings. We will use the coordinates:
We next have to choose the radii, along with the pattern of contacts we want. A nice symmetrical possibility is to have the ball bearing associated with every k-face make contact with its nearest neigbours among the ones associated with every (k+1)-face. The angles between the nearest neighbours of these various features are:
Once we choose the radius of the ball bearings centred on one of these features, the other radii are all determined by the need for them to sum to these angles. (We give the radii as angles rather than distances because everything we’re doing takes place in the unit 3-sphere, so this angle is more important than any straight-line distance in R4.) We will choose the radius of the bearings centred on the vertices to be π/12, which means the bearings centred on the edges will have the same radius, in order that the two sum to the angle between nearest neighbours, π/6. The complete set of radii are:
How many contacts are there?
This means that altogether there are 16×4 + 32×3 + 24×2 = 8×6 + 24×4 + 32×2 = 208 points of contact between spheres. Along with the 80 equations fixing the centres of the bearings, this gives us 288 vector equations, or 1152 equations in all. For each of the 80 angular velocities we have six independent components, for a total of 480 variables.
This system might sound wildly overdetermined, but in fact 8 of the centre-fixing equations turn out to be 0=0 immediately: one coordinate of each of the linear velocities of the hypercube centres is automatically zero. And those redundancies are just the most obvious of many. The rank of the matrix of coefficients for the system of equations turns out to be just 469, so in fact the system has an 11-dimensional solution space!
To choose a particular solution, we can try to impose some further symmetries. It would be nice if all the ball bearings at the k-centres for a given k had the same angular speed, and we could impose this by requiring that the sum of the squares of the components of their angular velocity matrices was the same. However, trying to do this for every k turns out to yield only the trivial solution where all the ball bearings are motionless. If we allow the ball bearings at the 2-faces to have different speeds, while imposing uniform speeds for k = 0, 1 and 3, we are also free to choose the particular speeds of the ball bearings at the vertices and the 3-faces. In the 96 solutions of the set of quadratic equations that impose these requirements, the speeds at the 2-faces always end up taking on just two different values.

In the animation above, we’ve projected some of the ball bearings for such a solution down to three dimensions, simply by dropping the fourth coordinate. This projection turns the spheres into ellipsoids. The colouring scheme here is:
Note that the blue spheres around the “equator” here are rotating faster than the two at the “poles” (which is why the pattern on them is drawn with different-sized squares, in order to match up at the first and last frames of the animation).
Why is this solution one of 96 that share the same speeds of rotation? A 4-cube has 384 symmetries (including both rotations and reflections; a derivation is given here). It turns out that there is a 4-element subgroup of symmetries that preserve our chosen solution; this subgroup is generated by a symmetry that acts as a reflection in a plane spanned by two vertices at opposite corners of one 2-face (preserving one vertex and inverting the other), while simultaneously acting as a rotation by 90° in the orthogonal plane. So applying all 384 symmetries to our chosen solution will produce 384/4 = 96 distinct solutions.
For a given configuration of ball bearings, is there any way to predict the dimension of the solution space, short of actually solving the associated system of linear equations?
Let’s start by considering ball bearings in R3, where geometrical intuition comes more easily. In this case, the angular velocity of each ball bearing can be described equally well by either an antisymmetric 3 × 3 matrix or by an angular velocity vector, ω. Suppose we have b ball bearings with radii ri, centres ci and angular velocity vectors ωi. Then for all bearings i and j that make contact, we have the constraint:
ωi × (ri ei, j) = ωj × (–rj ei, j)
where ei, j = (cj – ci) / |cj – ci|
Here the vector ei, j is a unit vector pointing along the “edge” that joins the bearings — not necessarily an edge of some polyhedron that we’re using to construct a symmetrical configuration, but simply the edge of a graph in which each ball bearing is a vertex, and pairs of bearings that make contact are connected by edges of the graph.
The equation above states that the linear velocities of both bearings are identical at the point of contact. We have as many of these equations as there are points of contact, and no further constraints are imposed. Naively, then, if we have b bearings and p points of contact we would seem to have 3 b variables from the angular velocity vectors, and 3 p component equations from the p vector equations at the points of contact.
However, the three component equations from each vector equation are not independent. If we chose an orthonormal basis for ωi and ωj in which ei, j was one of the vectors, then the equation for the ei, j component would simply be 0=0, because the cross product of ei, j with itself is zero. The constraint equation has nothing to say about components of the angular velocities parallel to the edge, because the bearings can spin at any rate at all around the edge without changing the linear velocity at the point of contact.
We can write out the coefficients of these equations with respect to the coordinates of the angular velocities in an arbitrary basis:
0 –ri (ei, j)z ri (ei, j)y 0 –rj (ei, j)z rj (ei, j)y ri (ei, j)z 0 –ri (ei, j)x rj (ei, j)z 0 –rj (ei, j)x –ri (ei, j)y ri (ei, j)x 0 –rj (ei, j)y rj (ei, j)x 0
This matrix multiplied by the vector ((ωi)x, (ωi)y, (ωi)z, (ωj)x, (ωj)y, (ωj)z) and equated to (0,0,0) gives the constraint equations. Taking just the first three columns, the three rows Rk will satisfy the equations:
Rk · ωi = the kth component of ωi × (ri ei, j)
Putting ωi = ei, j, the right-hand sides of these equations all become 0, and we have, for all k:
Rk · ei, j = 0
So all the Rk are orthogonal to ei, j. This means the dimension of the space they span is at most 2, and it’s clear by inspection that the dimension must be greater than 1. So these Rk, defined as the first three columns of the constraint matrix, span the 2-dimensional subspace of vectors orthogonal to ei, j.
The same is true for the last three columns, which differ from the first three only by the overall factor of rj in place of ri. We can always eliminate one row of the constraints by subtracting a linear combination of the other two rows, and we can describe the resulting portion of the reduced matrix schematically as:
ri fi, j rj fi, j ri gi, j rj gi, j
where {fi, j, gi, j} form a basis of the 2-dimensional subspace orthogonal to ei, j. Whatever such basis we choose, we can construct a reduced matrix in this form from linear combinations of the original three rows of the matrix.
In general, then, we only expect to get 2 p constraint equations from each point of contact. So we would expect a generic configuration of bearings in R3 with b bearings and p points of contact to have a solution space of dimension:
dgeneric = 3 b – 2 p
This prediction is borne out by explicit calculations for a number of configurations. For example:
But in other configurations there can be some further linear relationships between the constraints that effectively reduce their number, and increase the dimension of the solution space. For example, suppose we have bearings arranged in a planar n-gon, with an even value of n. We can write the reduced constraint equations matrix for, say, a quadrilateral, like this:
r1 f1,2 r2 f1,2 0 0 r1 g1,2 r2 g1,2 0 0 0 r2 f2,3 r3 f2,3 0 0 r2 g2,3 r3 g2,3 0 0 0 r3 f3,4 r4 f3,4 0 0 r3 g3,4 r4 g3,4 r1 f4,1 0 0 r4 f4,1 r1 g4,1 0 0 r4 g4,1
Here we’re again writing {fi, j, gi, j} for any choice of basis of the subspace orthogonal to ei, j.
If the bearings all lie in a plane, there will be some vector v that is orthogonal to every edge vector ei, j. That means we can write v in terms of each one of our bases of the subspaces orthogonal to the edge vectors:
v = αi, j fi, j + βi, j gi, j
For our example of a quadrilateral, we can then construct an 8-component vector:
w = (α1,2, β1,2, –α2,3, –β2,3, α3,4, β3,4, –α4,1, –β4,1)
Multiplying w times our reduced constraint matrix (that is, forming the sum of the eight rows of the matrix multiplied by the corresponding component of w) we get, for the four columns:
α1,2 r1 f1,2 + β1,2 r1 g1,2 – α4,1 r1 f4,1 – β4,1 r1 g4,1 = r1 (v – v) = 0
α1,2 r2 f1,2 + β1,2 r2 g1,2 – α2,3 r2 f2,3 – β2,3 r2 g2,3 = r2 (v – v) = 0
α3,4 r3 f3,4 + β3,4 r3 g3,4 – α2,3 r3 f2,3 – β2,3 r3 g2,3 = r3 (v – v) = 0
α3,4 r4 f3,4 + β3,4 r4 g3,4 – α4,1 r4 f4,1 – β4,1 r4 g4,1 = r4 (v – v) = 0
So we have found a linear combination of the 8 rows of the constraints matrix that is equal to zero, showing that the constraints in this case are not independent. We can do essentially the same thing for any even value of n, adding one to the dimension of the solution space for a planar n-gon, raising it to d = n+1.
What’s more, we can apply this method to larger configurations that contain even, planar n-gons. For example:
In these simple examples the system gains an extra dimension for every even, planar n-gon, but that won’t always be the case. In certain configurations, the vectors {wi} that we construct for several n-gons will themselves be linearly dependent, so they will only reduce the number of constraints (and hence increase the dimension of the solution space) by the dimension of the space that they span.
What’s so special, geometrically, about an even, planar n-gon that it leads to an extra degree of freedom in the system of bearings? To answer this question, first we need to think of the constraint that applies at each point of contact in a slightly different way: as stating that the projection of the vector ri ωi into the plane normal to the edge ei, j must be equal to the opposite of the projection of rj ωj into the same plane. This is the same thing as equating the linear velocities at the point of contact, but these projected ri ωi vectors are at right angles to the linear velocities. We can derive this statement rigorously by making use of a well-known identity obeyed by dot products of cross products:
(A × B) · (C × D) = (A · C) (B · D) – (A · D) (B · C)
If we pick a unit vector z that is orthogonal to ei, j, we have:
(ωi × ei, j) · (z × ei, j) = (ωi · z) (ei, j · ei, j) – (ωi · ei, j) (ei, j · z) = [ωi – (ωi · ei, j) ei, j] · z
The expression in square brackets is the projection of ωi into the plane orthogonal to ei, j, and what we have shown is that the component of that vector in the z direction is equal to the component of the original cross product in the z × ei, j direction. Since this holds for any choice of z, our original constraint:
ωi × (ri ei, j) = ωj × (–rj ei, j)
can be rewritten as:
ri ωi – (ri ωi · ei, j) ei, j = – [rj ωj – (rj ωj · ei, j) ei, j]
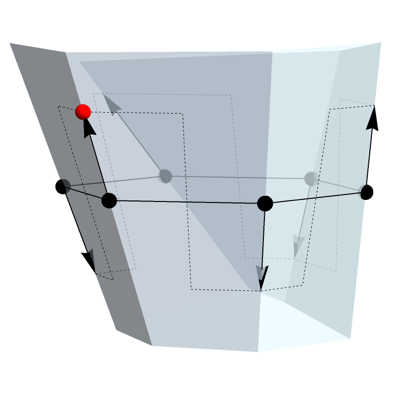
Now suppose we have an even, planar n-gon and we choose a plane normal to each edge in which we require the projected ri ωi vectors to lie. Each of these planes is specified by a single parameter (say, the angle it makes with the plane of the n-gon), and their mutual intersections at consecutive edges pin down the lines in which all of the angular velocity vectors must lie. If we start at the first bearing and specify the size and direction of the first vector, r1 ω1, we can move around the loop, projecting, negating and then using the negated projection to reconstruct the next ri ωi. The absolute value of the vectors’ components orthogonal to the plane of the n-gon remain constant, because the process of projection always just removes a component parallel to the plane, and since there are an even number of steps we are guaranteed to return to the vector we started with: the red dot that marks the end of the process in the diagram on the left coincides with the tip of the original vector.
Since we are free to choose one angle for each of the projections at the n points of contact, and also the size of the first vector, which sets the overall scale of the solution, we have n+1 free parameters.

In contrast to that, if we try to do the same thing with a generic, non-planar n-gon, we get the kind of result shown in the diagram on the right: the red dot that marks the vector we end up with after coming full circle does not agree with the original vector. So we need to give up one of our free choices of angle for the projections at the points of contact, and use the requirement of consistency around the loop to determine the angle instead. This leaves us with one less free parameter than in the even, planar case.
For an odd planar n-gon, if we apply the same scheme we used for the even case we end up with a contradiction: the net effect of traversing the loop gives us back the exact opposite of the original vector. The only way we can get a non-trivial solution is to have all the angular velocity vectors lie in the plane of the n-gon. The degrees of freedom in this case are an angle for the angular velocity at each bearing, as well as an overall scale, but as with the non-planar case we can only choose n–1 angles, with one angle fixed by the need for consistency around the loop.
So, the even, planar n-gon has n+1 degrees of freedom, but all other n-gons have only n degrees of freedom.
How do these techniques translate to S3? For bearings in S3, instead of a 3-parameter angular velocity vector ωi we have a 6-parameter antisymmetric angular velocity matrix Mi, but we also have a constraint equation for each bearing that’s needed to ensure that its centre remains fixed:
Mi ci = 0
Since this is a vector equation in R4 it corresponds to four component equations, but they are not independent. The fact that Mi is antisymmetric means that:
ci Mi ci = 0
This is equivalent to saying that the sum of the four constraints multiplied by the components of ci is zero, so there are only three independent constraints. This means that the dimension we start with, before applying constraints at the points of contact, is once again 3 b, just as it is in R3.
The constraints at the points of contact are:
Mi ti,j = Mj ti,j
The antisymmetry of Mi and Mj give us:
ti,j (Mi – Mj) ti,j = 0
which again means that the number of linearly independent constraints from this vector equation is 3, rather than 4. However, that’s not the full extent of the redundancy. The points of contact, ti,j, are always linear combinations of the two bearing centres ci and cj, say:
ti,j = ηi,j ci + ζi,j cj
Given the two constraints on two bearings’ centres and the constraint on the point of contact between them, we can form a linear combination that comes to zero:
ci (Mi ti,j – Mj ti,j) + ζi,j cj Mi ci + ζi,j ci Mj cj
= ζi,j [ ci (Mi cj – Mj cj) + cj Mi ci + ci Mj cj ]
= ζi,j [ ci Mi cj + cj Mi ci ]
= ζi,j [ (ci + cj) Mi (ci + cj) ]
= 0
This leaves only 2 independent constraints for each point of contact. So, just as for R3, for generic configurations in S3 the dimension of the solution space will be:
dgeneric = 3 b – 2 p
What are the equivalents of the even, planar n-gons that we found to increase the dimension of the solution space in R3? A set of bearings whose centres ci all lie in a single 3-dimensional hyperplane orthogonal to some vector v in R4 will all lie on a “great sphere” in S3, the closest thing to a plane in spherical geometry. But in S3 we can also have an n-gon where the centres of the bearings all lie in the same 2-dimensional plane in R4, so that they are strung out along a single great circle, wrapping all the way around the space. In that case, the n-gon would lie in two separate 3-dimensional hyperplanes, so we would expect the dimension of the solution space to increase by two.
To make the linear relationship between the constraints precise, we will link our construction in R3 to the configuration in S3 by “parallelising” the 3-sphere: finding a way to map the tangent space at any point on the sphere to the space of vectors in R3. The tangent vectors at a point in S3 are just linear multiples of the tangents to any curve that lies within the sphere, and if we view the sphere as sitting inside R4, these are just the vectors in R4 that are orthogonal to the vector from the centre of the sphere to the point in question. Obviously each such subspace of vectors in R4 is 3-dimensional, but what we want is to identify these various 3-dimensional spaces systematically with R3 in a way that varies smoothly across the 3-sphere.
The easiest way to do this is to make use of quaternion multiplication: an algebraic structure that allows us to multiply and divide vectors in R4. Just as the complex numbers have a single independent square root of minus one, the quaternions have three independent square roots of minus one: I, J and K. We will make the identification:
1 ↔ (1,0,0,0)
I ↔ (0,1,0,0)
J ↔ (0,0,1,0)
K ↔ (0,0,0,1)
and apply the rules of quaternion multiplication:
I2 = J2 = K2 = –1
I J = –J I = K
J K = –K J = I
K I = –I K = J
Quaternion multiplication is non-commutative: p q will generally not be equal to q p, for quaternions p and q. It will also be useful to define an operation known as conjugation, which we denote by following a quaternion with a *:
1* = 1
I* = –I
J* = –J
K* = –K
The conjugate of a product of quaternions is just the product of the conjugates in reverse order:
(a b)* = b* a*
and the product of a quaternion with its conjugate is a non-negative real number, the square of the magnitude of the original quaternion:
q* q = q q* = |q|2
It follows that, for a unit vector, its multiplicative inverse can be found simply by taking its conjugate:
u* u = u u* = 1
u–1 = u*
Linear combinations of {I, J, K} are known as imaginary quaternions, just like real multiples of the single square root of minus one in the complex numbers. Similarly, quaternions with no imaginary component are known as real. Given a general quaternion, we can find its real and imaginary parts by adding or subtracting its conjugate and halving the result:
Re(q) = ½(q + q*)
Im(q) = ½(q – q*)
The ordinary vector dot product on R4 can be expressed in terms of quaternionic operations as:
p · q = Re(p* q) = ½(p* q + q* p) = Re(q* p)
It follows that multiplication on the left or right by a unit vector always acts as a rotation in R4, preserving the dot product between quaternions, and hence the lengths of vectors and the angles between them.
(u p) · (u q) = Re((u p)* (u q)) = Re(p* u* u q) = Re(p* q) = p · q
(p u) · (q u) = Re((p u)* (q u)) = Re(u* p* q u) = ½(u* p* q u + u* q* p u) = ½ u* (p* q + q* p) u = u* Re(p* q) u = p · q
Now we can view S3, the set of unit-magnitude vectors in R4, as the set of unit-magnitude quaternions. The tangent space at the quaternion identity, (1,0,0,0), will consist of the imaginary quaternions, since they are orthogonal to (1,0,0,0). We will treat this particular 3-dimensional space as equivalent to R3 simply by dropping the first coordinate (which for imaginary quaternions is always zero). We deal with the tangent space at some other unit quaternion, say u, by mapping any curve through u, whose linear approximation will take the form C(ε) = u + ε w, to a curve through the identity. We do this by multiplying on the left with u–1, giving u–1 C(ε) = 1 + ε u–1 w. If w was orthogonal to u, the new tangent vector u–1 w will be a purely imaginary quaternion:
Re(u–1 w) = Re(u* w) = u · w = 0
Given a 4 × 4 antisymmetric angular velocity matrix M, associated with a ball bearing whose centre is c, we have the condition:
M c = 0
We can now associate a 3-dimensional angular velocity vector ω with M as follows. We have a linear map on R4 that consists of left-multiplication by c construed as a quaternion; we will refer to this map (and the corresponding matrix in the standard basis for R4) as Tc:
Tc(v) = c v
We can form a new matrix from M that describes a linear operator at the identity, by first mapping the identity to c with Tc, then acting with M, then using Tc–1 to take the result back to the identity. We will write:
Mid = Tc–1 M Tc
So long as M is an antisymmetric matrix and M c = 0, the new matrix Mid will take the form:
0 0 0 0 0 0 –ωz ωy 0 ωz 0 –ωx 0 –ωy ωx 0
This is just a general antisymmetric matrix with its first row and column zero, though we’ve named the particular non-zero entries in the matrix so that:
Mid v = ω × Im(v)
Strictly speaking this looks as if we’re equating a four-dimensional vector on the left-hand side with a three-dimensional vector on the right, but what we mean is that prepending a zero to the coordinates of the RHS will make this a four-dimensional equality.
To see why Mid takes this form, first note that Mid must be antisymmetric, because:
MidT = (Tc–1 M Tc)T = TcT MT (Tc–1)T = Tc–1 (–M) Tc = –Mid
Here we’ve used the fact that, since multiplication by a unit vector is a rotation, and the inverse of a rotation is its transpose, TcT = Tc–1. And the reason the first row and column of Mid must be zero is that:
Mid (1,0,0,0) = Tc–1 M Tc (1,0,0,0) = Tc–1 M c = Tc–1 0 = 0
Now, we can work backwards and define M in terms of Mid, and hence in terms of ω:
M = Tc Mid Tc–1
Applying this to some specific vector y, we have:
M y = Tc Mid Tc–1 y
= Tc Mid c–1 y
= c [ω × Im(c* y)]
We can now take our original equation for the points of contact:
Mi ti,j = Mj ti,j
with ti,j = ηi,j ci + ζi,j cj
and rewrite it as:
ci [ωi × Im(ci* ti,j)] = cj [ωj × Im(cj* ti,j)]
ci [ωi × Im(ci* (ηi,j ci + ζi,j cj))] = cj [ωj × Im(cj* (ηi,j ci + ζi,j cj))]
ci [ωi × (ζi,j Im(ci* cj))] = cj [ωj × (ηi,j Im(cj* ci))]
ci [ωi × (ζi,j Im(ci* cj))] = cj [ωj × (–ηi,j Im(ci* cj))]
This result is reminiscent of our constraint in R3:
ωi × (ri ei, j) = ωj × (–rj ei, j)
where ei, j = (cj – ci) / |cj – ci|
We can bring it closer by using the quaternionic formula for the dot product:
Re(p* q) = p · q
Im(p* q) = p* q – p · q
|Im(p* q)|2
= Im(p* q)* Im(p* q)
= (p* q – p · q)* (p* q – p · q)
= (q* p – p · q) (p* q – p · q)
= |q|2 |p|2 – (p · q)2
For unit vectors such as ci and cj this becomes:
|Im(ci* cj)|2 = 1 – (ci · cj)2
All points of contact must be unit vectors:
ti,j · ti,j = 1
(ηi,j ci + ζi,j cj) · (ηi,j ci + ζi,j cj) = 1
ηi,j2 + ζi,j2 + 2 ηi,j ζi,j (ci · cj) = 1
And all points of contact for a given ball bearing will have a dot product with the centre ci equal to cos ρi, where ρi is the angular radius of the bearing. We will write χi for cos ρi, so we have:
ci · ti,j = χi
ci · (ηi,j ci + ζi,j cj) = χi
ηi,j + ζi,j (ci · cj) = χi
Solving the last equation for ηi,j and inserting the result back into the equation for ti,j being a unit vector gives us:
[χi – ζi,j (ci · cj)]2 + ζi,j2 + 2 [χi – ζi,j (ci · cj)] ζi,j (ci · cj) = 1
ζi,j2 (1 – (ci · cj)2) = 1 – χi2
ζi,j2 |Im(ci* cj)|2 = 1 – χi2
Note that this is true for all j. And although we’ve written it in terms of the coefficient ζi,j, the coefficients η and ζ swap roles if we swap the roles of i and j. So if we define:
ri = √[1 – χi2] = sin ρi
ei, j = Im(ci* cj) / |Im(ci* cj)|
we can rewrite our constraint condition as:
ci [ωi × (ri ei, j)] = cj [ωj × (–rj ei, j)]
This is a four-dimensional vector equation, but we can show that it only contains two independent constraints by exhibiting two (independent) linear relations that reduce it to 0=0. First, note that for any imaginary quaternion i and any quaternion at all, since left-multiplication by q preserves dot products we have:
q · (q i) = (q 1) · (q i) = 1 · i = 0
Since the cross products in the constraint equation are imaginary, the dot products of ci and cj with the constraint equation each eliminate one of the terms immediately, yielding, respectively:
0 = ci · (cj [ωj × (–rj ei, j)])
cj · (ci [ωi × (ri ei, j)]) = 0
Now, recall that ei, j is a scalar multiple of Im(ci* cj), so ωi × (ri ei, j) is orthogonal to Im(ci* cj) by the usual orthogonality of the cross product. But since the cross product is also purely imaginary, its dot product with Im(ci* cj) is no different from its dot product with ci* cj. And we have:
cj · (ci [ωi × (ri ei, j)])
= Re(cj* ci [ωi × (ri ei, j)])
= Re((ci* cj)* [ωi × (ri ei, j)])
= (ci* cj) · [ωi × (ri ei, j)]
= 0
We can eliminate the other equation by the same method, swapping the roles of ci and cj, and noting that Im(cj* ci) is simply –Im(ci* cj).
If we write the constraint equation as a matrix times the vector of ω coordinates, equated to zero, then taking just the first three columns of that matrix and calling the four rows Rk, they will satisfy the equations:
Rk · ωi = the kth component of ci [ωi × (ri ei, j)]
for any ωi. Putting ωi = ei, j, the right-hand sides of these equations all become 0:
Rk · ei, j = 0
So, as with the case in R3, these three-dimensional row vectors Rk will span the 2-dimensional space orthogonal to ei, j. The same will be true of the vectors we get from the last three columns of the matrix, but unlike the case in R3, the last three columns and the first three columns do not differ only by a scalar multiple. If we call the vectors whose components come from the last three columns Sk, the precise relationship turns out to be ci Rk / ri = cj Sk / rj, or equivalently Sk = (rj / ri) cj* ci Rk, for all k.
To show this, we need to express the cross product in terms of quaternionic operations. For two purely imaginary quaternions i and j, we have:
i × j = i j + i · j
If we’re starting from arbitrary quaternions p and q, we can find the cross product of their imaginary parts as:
Im(p) × Im(q)
= Im(p) Im(q) + Im(p) · Im(q)
= Im(p) Im(q) + p · q – Re(p) Re(q)
= ¼(p – p*) (q – q*) – ¼(p + p*) (q + q*) + ½(p* q + q* p)
= ½(q* p – p q*)
It follows that, for any quaternion s, and unit quaternions ci and cj:
ci (Im(ci* s) × Im(ci* cj))
= ½ ci (cj* s – ci* s cj* ci)
= ½ (ci cj* s – s cj* ci)
= ½ cj (cj* ci cj* s – cj* s cj* ci)
= cj (Im(cj* s) × Im(ci* cj))
Using the definition of ei, j and what we know about the dot products of Rk, we have, for any s:
|Im(ci* cj)| (ci Rk / ri) · s
= |Im(ci* cj)| (Rk / ri) · Im(ci* s)
= the kth component of ci [Im(ci* s) × Im(ci* cj)]
= the kth component of cj [Im(cj* s) × Im(ci* cj)]
= |Im(ci* cj)| (Sk / rj) · Im(cj* s)
= |Im(ci* cj)| (cj Sk / rj) · s
We go from the first line to the second (and the second-last line to the last) by rotating both vectors in the dot product by the same rotation, and also using the fact that Rk and Sk are purely imaginary so their dot product with any vector is the same as their dot product with its imaginary part. And finally, since the equality between dot products with s holds for every s, the vectors themselves must be equal.
Now suppose we have a four-dimensional vector v that is orthogonal to every ball bearing centre ci. We will then have for all i:
ci · v = Re(ci* v) = 0
In other words, ci* v is purely imaginary, for all i. What’s more, ci* v is orthogonal to Im(ci* cj), and hence ei, j:
(ci* v) · Im(ci* cj)
= (ci* v) · (ci* cj – (ci · cj))
= Re(v* ci ci* cj – v* ci (ci · cj))
= Re(v* cj) – Re(v* ci) (ci · cj)
= (v · cj) – (v · ci) (ci · cj)
= 0
Similarly, cj* v is orthogonal to ei, j. Since ci* v is orthogonal to ei, j, there will be some linear combination of the vectors Rk equal to ri ci* v, say:
ri ci* v = Σk αi, j, k Rk
If we take the same linear combination of the Sk, we get:
Σk αi, j, k Sk = (rj/ri) cj* ci Σk αi, j, k Rk = (rj/ri) cj* ci (ri ci* v) = rj cj* v
This means that for an even, planar n-gon we can construct a vector w whose entries alternate between ±αi, j, k, and when we multiply the constraints matrix on the left by w, the set of three columns associated with bearing i will yield +ri ci* v from one of the two sets of four rows associated with that bearing’s points of contact within the n-gon, and –ri ci* v from the other set.
Of course as in R3, these constraint-reducing relations will only increase the dimension of the solution space to the extent that they themselves are linearly independent.
In our example based on a 4-cube, the dimension of the solution space was 11. Is it possible to derive that dimension, without explicitly solving the whole set of linear equations?
It’s worth stating, first, that the results of the previous section already allow us to set up a much smaller set of equations, with half as many variables (three for each vector ωi, as opposed to six for each antisymmetric matrix Mi) and less than half as many equations (we no longer require equations for each bearing, and starting with the vector equation in ωi and ωj for each point of contact, we can choose two vectors orthogonal to ci and cj, and replace the vector equation with its dot products with those two vectors). So we can shrink the system from the original 1152 equations in 480 variables to 416 equations in 240 variables.
But in any case, the dimension of 11 that we find from actually solving those equations will become much less mysterious if we can arrive at it by starting with the dimension we’d expect from the generic formula:
dgeneric = 3 b – 2 p = 3 × 80 – 2 × 208 = –176
(implying that the generic system would be massively overconstrained), and then reducing the number of independent constraints due to the presence of even, planar n-gons.
A “planar” n-gon in this context is one whose corners all lie within the same three-dimensional hyperplane through the origin. It turns out that these n-gons will all lie either in a hyperplane normal to one of the 3-centres, or in a hyperplane normal to one of the 2-centres. The intersections of these two kinds of hyperplanes through the origin with the contact graph for the bearings are shown below.


In these images, we’ve used the labels V, E, F and C for 0-, 1-, 2- and 3-centres respectively. There are four distinct hyperplanes normal to the eight 3-centres and 12 distinct hyperplanes normal to the 24 2-centres, giving a total of 4 × 24 + 12 × 8 = 192 small squares of the kind shown here. Obviously there are many more even n-gons that can be found in each hyperplane than the small squares, but on the face of it the 192 squares look like a good candidate for a “basis” of all those n-gons, in the sense that the vectors derived from them would appear to form a basis for all such vectors derived from other even n-gons in the same hyperplanes. For example, the vector derived from the six-sided union of two of these squares that share a common edge is just the sum of the vectors for the individual squares, with the opposite signs associated with the common edge cancelling out.
However, 192 is not quite the number we need, since 192 – 176 = 16, not 11. So we must be counting 5 more vectors as linearly independent here than are actually independent. Four cases are easy to identify: for each of the four hyperplanes normal to a 3-centre, the sum of all 24 small squares will come to zero, with all the shared edges cancelling out. So in each of those hyperplanes, one square can be written as a linear combination of the other 23, and discarded from the linearly independent set.
The final linear relationship is trickier to spot, because it involves a sum over all the squares in all twelve hyperplanes that are normal to 2-centres. Summing at the level of individual hyperplanes merges each set of four adjoining squares into a single 8-gon, and although geometrically this 8-gon is just a 2-face of the hypercube, it turns out to be crucial that the edges of these faces are split into two halves labelled with opposite signs – or to be precise, labelled with opposite vectors that are normals to the hyperplanes in which the faces lie.
Three faces meet at every edge of the hypercube, and in order for the sum of all the constraint-reduction vectors to be zero, the appropriately signed sums of the normals to those three faces must be zero. For a given edge it’s easy to exhibit three 2-centres that are orthogonal to the three faces containing that edge, and that sum to zero. For example (omitting the normalisation of these hypercube features to unit vectors):
Shared edge has centre: (1, 1, 1, 0)
Belongs to 2-faces with centres: (1, 1, 0, 0), (1, 0, 1, 0) and (0, 1, 1, 0)
2-centres normal to these 2-faces: (1, –1, 0, 0), (–1, 0, 1, 0) and (0, 1, –1, 0)
(1, –1, 0, 0) + (–1, 0, 1, 0) + (0, 1, –1, 0) = (0, 0, 0, 0)
But to show that we can make the sum zero consistently, we need an explicit formula for the choice of normal vector. Given a particular face F, edge-centre E and vertex V (still using hypercube features rather than unit vectors), we will assign to the half-edge VE the normal vector given by:
| N | = |
|
Here the subscripts on the vectors F, E and V just indicate their components, while {e1, e2, e3, e4} denote the standard basis for R4, and hence are vectors not numbers. This might remind you of a similar way of writing a cross product of two vectors in R3:
| A × B | = |
|
This choice of N gives us everything we need. The dot product of N with any vector w will just be the same determinant with the ei replaced by wi, so if w is any of F, E or V the result will be zero. This means that up to some overall scalar multiple, N must be the 2-face centre normal to the hyperplane containing the 2-face with centre F.
If we swap V for the other vertex that is joined to the original edge centre, this amounts to the transformation V → V + 2 (E – V) = 2 E – V. Adding any multiple of an existing row of a matrix to another row leaves the determinant unchanged, so this has the same effect as simply changing the sign of V, and hence of N.
If we swap E for the other edge centre that is joined to the original vertex, this is equivalent to E → E + (V – E) + (F – E) = V + F – E, which again simply changes the sign of the determinant. So as we move around the perimeter of a given face, N alternates in sign.
Finally, we need to show that the sum of the three normals we obtain this way from the centres of the three different 2-faces that share the half-edge VE is zero. First, note that because we are only changing F and leaving all the other rows fixed, the sum of the determinants is just the determinant of the matrix where the original F is replaced by the sum of its three versions. And because the three different F vectors are arranged symmetrically around the edge-centre E, their sum is just a multiple of E. For example, using the edge we described earlier:
Shared edge has centre: (1, 1, 1, 0)
Belongs to 2-faces with centres: (1, 1, 0, 0), (1, 0, 1, 0) and (0, 1, 1, 0)
(1, 1, 0, 0) + (1, 0, 1, 0) + (0, 1, 1, 0) = (2, 2, 2, 0)
The determinant of any matrix where one row is a multiple of another is zero, so we have the desired result.
For our example based on the 4-cube, we started out with 1152 equations in 480 variables. Then we used quaternion methods to parallelise the tangent space and shrink this to 416 equations in 240 variables. We went on to show that there were 192 – 5 = 187 independent linear relations between those 416 equations, effectively shrinking them to just 416 – 187 = 229. That explained why the system has 240 – 229 = 11 degrees of freedom.
Still, even 229 equations in 240 variables seems excessive for such a symmetrical system. The arrangement of ball bearings, with one at every k-centre in contact with its neighbours at (k–1)-centres and (k+1)-centres, is essentially the same for every k-centre (for a specific value of k), so we ought to be able to exploit that symmetry to simplify the set of equations we need to solve.
What we will find is that the possible states of motion of the system can be broken down into a number of lower-dimensional spaces of distinctive “modes”. These spaces, known as irreducible representations, are the smallest spaces such that if we rotate or reflect the system in a way that carries the 4-cube back into itself, the modes in question never leave the space they started in.
A similar structure can be seen in almost any system with some form of symmetry. To take one of the simplest examples, if we rotate a vibrating ring (for which the underlying equations have perfect rotational symmetry) the vibrations of a given wavelength remain in the space of vibrations of that wavelength. A function such as cos(n θ) will be shifted by the angle of rotation α into a new function, cos(n (θ – α)), but this new function still lies in the two-dimensional space spanned by cos(n θ) and sin(n θ):
cos(n (θ – α)) = cos(n α) cos(n θ) + sin(n α) sin(n θ)
An even closer analogy to the system we are considering can be found with the functions known as spherical harmonics that play a role in the solutions to many physical problems with spherical symmetry.
Once we identify the irreducible representations, we can apply the constraints to each of them independently, yielding much smaller sets of linear equations. In fact, we will ultimately reduce our original system of equations down to two absurdly small sets: one with two equations in three variables, and the other with four equations in six variables.
The group of rotations and reflections that are symmetries of an n-cube is known as the hyperoctahedral group. It is also referred to as the Coxeter group BCn, so the particular group we are interested in is called BC4. A 4-cube has 24 4! = 384 symmetries, as shown here.
Suppose we take our system of 80 ball bearings at the k-centres of a 4-cube, and we allow the bearings to rotate in some completely arbitrary fashion: that is, without imposing the requirement that they are rolling smoothly against each other at the points of contact. At each of the 208 points of contact, then, there will be a vector describing the difference in the linear velocities of the two bearings. We can think of the matrix for our constraint equations as being a linear operator L from a 240-dimensional vector space that describes every possible way the 80 bearings can rotate, into a 416-dimensional space that describes every possible set of linear velocities at the points of contact. In the first case, the dimension of the space is 3 × 80 = 240, because the angular velocity of each bearing has three degrees of freedom; despite the overall system being four-dimensional, these bearings are three-dimensional spheres and their angular velocities are really angular velocities in the three-dimensional tangent space. In the second case, the dimension is 2 × 208 = 416, because at the point of contact the difference in linear velocities must be tangent to both bearings, giving it only two degrees of freedom. We will refer to these two spaces as V240 and V416.
Now, suppose we take a set of values for the angular velocities of the 80 bearings, and rotate and/or reflect them using one of the symmetries of the 4-cube. That is, we “pick up” the angular velocities assigned to all the bearings and move them around, as if they themselves were a solid object. Since we are using a symmetry of the 4-cube, each k-centre will end up at a matching k-centre, but the angular velocities will have both moved from bearing to bearing and they will have changed direction as a result of the rotation or reflection. A crucial detail is that under reflections, the angular velocities transform as pseudovectors, while the locations of the bearings’ centres transform as true vectors.
The result of this is to map one vector in V240 into another such vector. Whatever vector we started with, this process gives us another one, so from a symmetry of the 4-cube we have obtained a map from V240 to itself – and because the symmetries acting on R4 are linear, so is this operator on V240. If the symmetry of the 4-cube is g, we will call this linear operator ρ240(g). What’s more, we can do this for any choice of g, so ρ240 gives us a map from the entire 384-element group, BC4, to the set of linear operators on V240. We can write this formally as:
(ρ240(g) f)(b) = ρPseudo(g) f(ρFund(g)–1 b)
f is a vector in V240 that we are decribing as a function from bearing centres, b, in R4 to angular velocity pseudovectors (which we can embed in R4 despite them having only three degrees of freedom, since the tangent space is naturally embedded in R4). Here ρFund(g) is a linear operator describing the ordinary way the symmetry g acts on vectors in R4, while ρPseudo(g) is a linear operator appropriate to pseudovectors, such as angular velocity. The new function we get after applying the symmetry obtains its angular velocity for bearing b from the bearing ρFund(g)–1 b that will be moved into bearing b, and then rotates the original pseudovector with ρPseudo(g).
The linear operators on V240 that we obtain this way are all invertible and unitary: they preserve the inner product between vectors on V240 defined as:
<f, g> = ΣBearings b f(b)* · g(b)
Here “*” is complex conjugation. As everything in this example is real-valued, we could say that these operators are orthogonal, but in principle complex numbers can arise in similar calculations, and some important results depend on the fact that we are always (potentially) allowing that, so we will continue to describe the operators ρ240(g) as unitary.
The map ρ240 from the group of symmetries BC4 to the unitary linear operators on V240 is an example of a group representation. [As is the map ρFund, which is known as the fundamental representation.] The crucial property here is that multiplication within the group agrees with multiplication of the linear operators on the vector space, so that for any two group elements g and h we have:
ρ240(g h) = ρ240(g) ρ240(h)
Now, when we use a symmetry of the 4-cube to pick up all the angular velocities and move them around, the same thing will happen to the linear velocity differences at the points of contact: they will move from their original points of contact to new ones, and they will change direction due to the rotation or reflection being applied. So we have another representation of the same group, ρ416, which acts on V416. Again, ρ416(g) will be a unitary operator for every g.
How do these two representations interact with our linear operator L, which takes a set of angular velocities in V240 and produces the resulting set of point-of-contact velocity differences in V416? If we rotate or reflect the angular velocities then use L to give us the linear velocity differences, we must get the same answer as if we used L on the original set of angular velocities, and then rotated or reflected the linear velocity differences with the same symmetry. In other words, for every g we must have:
L ρ240(g) = ρ416(g) L
We say that L commutes with these representations, or that L is an intertwiner or an equivariant map.
So far, all we’ve done is put into formal language something that’s really pretty obvious: L has to be compatible with the way rotations and reflections affect the motion of the bearings as we describe them with vectors in V240 and V416. But the fact that L commutes with these representations will allow us to give a much more compact description of it than a 416 × 240 matrix.
To reach this new description, we need to introduce the concept of an invariant subspace. In the context of a representation ρ on a vector space V, we say that a subspace W of V is invariant if for all group elements g and all vectors w in W, ρ(g) w also lies in W. In other words, the representation’s action never moves a vector from W out of W. This means that, if we like, we can actually ignore the rest of the larger vector space, V, and talk about ρ restricted to W as a representation in its own right: a subrepresentation of the original one.
An irreducible representation, or irrep for short, is a representation that contains no non-trivial subrepresentations. That is, if the representation acts on V, there are no invariant subspaces of V other than {0} and V itself.
Our representations ρ240 and ρ416 are certainly not irreducible! For example, the 48-dimensional subspace of V240 in which only the 16 bearings at the vertices have non-zero angular velocities is clearly an invariant subspace, because any symmetry of the 4-cube carries vertices to vertices. However, if we look for invariant subspaces in V240 and V416 and then keep asking if the subrepresentations obtained this way are themselves reducible or not, the process can’t go on forever, since these spaces only have a finite number of dimensions. Eventually, we must end up finding a set of invariant subspaces that contain no smaller non-trivial ones. This is known as completely reducing the representations.
We say that two representations are equivalent if they are really “doing the same thing”, even if they act on different vector spaces. Formally, if representation ρ1 acts on vector space V1 and representation ρ2 acts on vector space V2, they are equivalent if there is an isomorphism T: V1 → V2 that commutes with the two representations:
T ρ1(g) = ρ2(g) T
Now, suppose we have two irreducible representations, ρ1 acting on V1 and ρ2 acting on V2, along with a linear operator L: V1 → V2 that commutes with these representations:
L ρ1(g) = ρ2(g) L
A famous result in group representation theory, known as Schur’s lemma, says that either:
This is easy to prove,[1] given the irreducibility of the representations. First, note that the kernel of L, the subspace of V1 consisting of vectors v such that L v = 0, is an invariant subspace. For if we have such a v, it follows that:
L (ρ1(g) v) = ρ2(g) L v = ρ2(g) 0 = 0
That is, ρ1(g) v is also in the kernel. But since ρ1 is irreducible, the only invariant subspaces of V1 are V1 itself and {0}. In the first case, L maps all of V1 to zero, so L is the zero map. In the second case, where L has a kernel of {0}, we need to consider the image of L, the subspace of all vectors w in V2 that take the form L u for some u in V1. This subspace of V2 is invariant, because if w = L u, then:
ρ2(g) w = ρ2(g) L u = L (ρ1(g) u)
So the image of L must be either {0} or all of V2. If it’s {0}, then L is zero. If it’s all of V2, then L is an isomorphism that commutes with the representations, which is the same thing as saying that the representations are equivalent.
There is a corollary to Schur’s lemma for the case when the representations are equivalent and the vector spaces themselves are actually the same: V1 = V2, so L is an isomorphism from V1 to itself. Any linear operator on V1 must have at least one eigenvalue over the complex numbers, say λ. We can then apply Schur’s lemma to M = L – λ I, where I is the identity operator on V1. Clearly M will commute with the representations (since L does, and any multiple of the identity commutes with everything), so M must be the zero map or an isomorphism. But M has a non-trivial kernel, containing the eigenvectors of L with eigenvalue λ, so it can’t be an isomorphism, it must be the zero map. In other words, we must have L = λ I.
Schur’s lemma looks simple, but it has some extraordinarily powerful consequences! Suppose K is any linear map whatsoever from V1 to V2, and ρ1 and ρ2 are irreducible representations of some group G with |G| elements. Then the linear operator formed by “averaging” K over the group:
KG = [1 / |G|] Σg∈G ρ2(g) K ρ1(g–1)
will commute with the representations:
KG ρ1(a)
= [1 / |G|] Σg∈G ρ2(g) K ρ1(g–1) ρ1(a)
= [1 / |G|] Σg∈G ρ2(g) K ρ1(g–1 a)
= [1 / |G|] Σg∈G ρ2(a) ρ2(a–1 g) K ρ1(g–1 a)
= ρ2(a) [1 / |G|] Σb = a–1 g ∈ G ρ2(b) K ρ1(b–1)
= ρ2(a) KG
This means we can apply Schur’s lemma to conclude that either KG is the zero map, or it is an isomorphism from V1 to V2 (which must then have the same dimension), and the two representations are equivalent. The fact that these results need to hold for any K imposes conditions that are independent of K itself, leaving us with the following orthogonality relations between the matrix elements of the representations:
[dim ρ1 / |G|] Σg∈G ρ2(g)kl ρ1(g–1)ij = δkj δli δρ1, ρ2
By δρ1, ρ2 we mean 1 if the two irreps are equivalent and 0 if they are not. If the irreps are unitary, the inverse is just the complex conjugate of the transpose, so this becomes:
[dim ρ1 / |G|] Σg∈G ρ2(g)kl ρ1(g)*ji = δkj δli δρ1, ρ2
In what follows, we will assume that all the representations we are dealing with are unitary. (In fact, it is always possible to define an inner product with respect to which this is true.[1])
Now, our linear map L: V240 → V416 commutes with the representations ρ240 and ρ416, but they are not irreducible. However, we can decompose V240 and V416 into direct sums of irreducible subspaces. Then we can restrict the domain of L to each of the subspaces of V240 in turn, and project the result into each of the subspaces of V416. These restricted maps will commute with the irreducible representations on these subspaces, allowing us to apply Schur’s lemma. So in each case, the restricted map will only be non-zero where it maps one irreducible representation into an equivalent one.
How do we decompose V240 and V416 into direct sums of irreducible subspaces? To do this, we need to know all the irreps of the symmetry group we’re dealing with. For a finite group like this, there are only a finite number of irreps, up to equivalence. We don’t need complete descriptions of the irreps, as long as we have their characters: the values of the traces of the matrices that each representation assigns to each element of the group. But the trace of any matrix M is unchanged by conjugation with an invertible matrix A:
M → A–1 M A
Tr (A–1 M A) = Tr M
It follows that the character of any representation is constant on each conjugacy class: the sets of elements in the group that can be transformed into each other by conjugation. [This is a different meaning of the word “conjugation” from the conjugation operator on complex numbers or quaternions; this operation is also known as a similarity transformation.] It turns out that the group of symmetries of the 4-cube has 20 irreps, and their values on the group’s 20 conjugacy classes are given here.
A suitably normalised inner product between characters:
<χ1, χ2> = [Σg∈G χ1(g)* χ2(g) ] / |G|
is orthonormal for the irreducible representations of any group G: it is 1 for any irreducible representation with itself, and 0 between any two irreducible representations that are not equivalent.[2] This follows from the orthogonality relations, if we put j=i and l=k then sum over i and k.
If we write Cl(G) for the set of conjugacy classes of G, and χi(C) for the constant value that the character takes across the whole class, we can express the inner product as a weighted sum across conjugacy classes:
<χ1, χ2> = [ΣC∈Cl(G) |C| χ1(C)* χ2(C) ] / |G|
Given the characters of the irreps, we can construct projection operators on V240 and V416 that project into subspaces consisting of direct sums of one or more copies of each of the irreps. For example, if the irrep ρi has character χi, we define the associated projection on V240:
Pi = [dim ρi / |G|] Σg∈G χi(g–1) ρ240(g)
= [dim ρi / |G|] ΣC∈Cl(G) χi(C)* Σg∈C ρ240(g)
To see that Pi really does what we claim, consider the sum we get from an irreducible representation, say ρj, over the elements of a single conjugacy class C:
S(C, ρj) = Σg∈C ρj(g)
This operator will commute with ρj(h) for any h:
S(C, ρj) ρj(h)
= [Σg∈C ρj(g)] ρj(h)
= [Σk∈C ρj(h k h–1)] ρj(h)
= ρj(h) [Σk∈C ρj(k)]
= ρj(h) S(C, ρj)
Here we have used the fact that if you conjugate everything in the conjugacy class C with some fixed element h, you just get back the elements of C in a different order.
Since S(C, ρj) commutes with ρj, it must be a multiple of the identity. If we take its trace, we find:
Tr(S(C, ρj)) = |C| χj(C)
Since the trace of the identity operator is dim ρj, it follows that S(C, ρj) must be equal to |C| χj(C) / (dim ρj) times the identity.
Consider the restriction of Pi to an irreducible subspace Vj of V240, on which the subrepresentation of ρ240 is equivalent to the irrep ρj.
Pi|Vj = [dim ρi / |G|] ΣC∈Cl(G) χi(C)* Σg∈C ρj(g)
= [dim ρi / |G|] ΣC∈Cl(G) χi(C)* S(C, ρj)
= [dim ρi / |G|] ΣC∈Cl(G) χi(C)* |C| χj(C) / (dim ρj) IVj
= [dim ρi / dim ρj] <χi, χj> IVj
In the last two lines, we are writing IVj for the identity on Vj. If the irreps ρi and ρj are equivalent, then <χi, χj> = 1 and dim ρi = dim ρj, so Pi|Vj itself is just the identity on Vj. If the irreps are not equivalent, then <χi, χj> = 0 and Pi|Vj is the zero map. So Pi acts as the identity on every irreducible subspace of V240 where ρ240 is equivalent to the irrep ρi, and as the zero map on every irreducible subspace where this is not the case.
We should stress that the complete projections Pi do not necessarily project into irreducible subspaces, because there might be several irreducible subspaces of V240 for which the subrepresentation is equivalent to ρi, in which case the image of Pi will be a subspace that is the direct sum of all of them. These possibly larger subspaces are known as isotypic subspaces.
We can construct projections for both V240 and V416. We will call the first set Pi and the second set Qi. Given matrices for the representations ρ240 and ρ416 and characters for all the irreps, it is straightforward to sum these and form the matrices for Pi and Qi.
We can then find bases for the isotypic subspaces by taking linearly independent subsets of columns from the matrices for the projections, or various linear combinations of the columns. If we write dim Pi for the dimension of the image of Pi, we will have up to twenty matrices BPi, of size 240 × (dim Pi), whose columns are basis vectors for the isotypic subspaces of V240, and similarly up to twenty matrices BQi, of size 416 × (dim Qi), whose columns are basis vectors for the isotypic subspaces of V416. In fact, for six of the twenty irreps, Pi turns out to be the zero map: there are no subspaces in V240 where ρ240 restricts to a representation equivalent to any of those six irreps. And there are two irreps that are similarly absent from V416. The latter two are among the first six, so all in all we end up discarding six irreps from any further role in the problem, and deal with just fourteen.
For each of those fourteen irreps, we construct a linear operator Li, which has dim Pi variables in the corresponding set of equations, and dim Qi constraints. The matrices for these operators are:
Li = [(BQiT BQi)–1 BQiT] L BPi
The term [(BQiT BQi)–1 BQiT] requires some explaining! We know that the image of L BPi is a subspace of V416 with a dimension of just dim Qi, but since L is a 416 × 240 matrix, L BPi is a 416 × (dim Pi) matrix. What we need to do is extract from the 416-component vectors spat out by that matrix their coordinates in the basis given by the columns of BQi. The (dim Qi) × 416 matrix [(BQiT BQi)–1 BQiT], which is the left inverse of BQi, does just that: if you feed it any vector that is a linear combination of the columns of BQi, it will yield the list of coefficients used to produce that linear combination. This follows from the fact that the left inverse lives up to its name: multiplying BQi on the left by this matrix yields the identity matrix of dimension dim Qi.
(BQiT BQi)–1 BQiT BQi = Idim Qi
Of the fourteen Li we obtain this way, the largest matrix is 72 × 48. But only two of the fourteen matrices have non-trivial kernels. These are:
Together, they account for the 3 + 8 = 11 degrees of freedom of the whole system.
Let’s look more closely at the two isotypic subspaces that play a role in the solution for the 4-cube.
The first subspace comes from one of the group’s three-dimensional irreps, and the entire subspace (before we solve for the constraints) is 9-dimensional, containing one copy of the irrep from each of three spaces of angular velocities: for the bearings at the 0-centres, the 1-centres, and the 2-centres. This irrep does not appear at all in the space of angular velocities for the 3-centres.
We can describe a basis for this irrep within the space of angular velocities for the 0-centres as follows. Suppose we split the four coordinates of R4 into two pairs, P1 and P2. There are six ways to choose P1, leaving P2 for the remaining pair. Our three basis functions and their opposites arise from negating the coordinates in P1 for each of the six possible choices:
| P1={1,2} | f1(w, x, y, z) = (–w, –x, y, z) |
| P1={1,3} | f2(w, x, y, z) = (–w, x, –y, z) |
| P1={1,4} | f3(w, x, y, z) = (–w, x, y, –z) |
| P1={3,4} | –f1(w, x, y, z) = (w, x, –y, –z) |
| P1={2,4} | –f2(w, x, y, z) = (w, –x, y, –z) |
| P1={2,3} | –f3(w, x, y, z) = (w, –x, –y, –z) |
The functions fi give three ways of assigning an angular velocity to each vertex of the 4-cube. Since the coordinates at a vertex are all of equal magnitude, the vectors these functions produce are always orthogonal to the vertex vector. For example:
(w, x, y, z) · f1(w, x, y, z) = –w2 – x2 + y2 + z2 = 0.
The vectors produced by the different functions are also mutually orthogonal:
f1(w, x, y, z) · f2(w, x, y, z) = w2 – x2 – y2 + z2 = 0
f1(w, x, y, z) · f3(w, x, y, z) = w2 – x2 + y2 – z2 = 0
f2(w, x, y, z) · f3(w, x, y, z) = w2 + x2 – y2 – z2 = 0
What happens if we act on one of these functions, fi, with our representation ρ240?
(ρ240(g) fi)(b) = ρPseudo(g) fi(ρFund(g)–1 b)
In general, ρFund(g)–1 will permute the coordinates and change some of their signs. The action of fi changes two signs but does not permute any of the coordinates. ρPseudo(g) will reverse the sign changes performed by ρFund(g)–1, and reverse the permutations, then because it is a pseudovector representation it will multiply all the coordinates by an extra factor of Det(g)=±1, which will change either four signs or none. Altogether, then, the net effect is that there will be no permutations of the coordinates and precisely two sign changes. But our three fi and their opposites include all six possible ways that precisely two sign changes can be made to four coordinates. So ρ240(g) fi will always lie in the three-dimensional space spanned by the three fi. This proves that the fi span an invariant subspace.
The other two copies of this irrep for angular velocities also have bases that we can identify with ways of splitting the four coordinates into two pairs, P1 and P2. The functions we will use to assign angular velocities to the 1-centres work as follows. Given an edge centre, locate the centre of a certain 3-face that touches that edge, by setting to zero the coordinates that lie within whichever Pi does not contain the sole zero coordinate of the edge centre. For example, if P1={1,2} then for the edge centre (0,–1,1,1) we use the 3-face centre (0,–1,0,0), while for the the edge centre (1,–1,1,0) we use (0,0,1,0). Take the vector pointing from the edge centre to this 3-face centre, and project it into the tangent space at the edge centre. Finally, if the zero coordinate of the edge centre is in P1 rather than P2, negate the result.
We have six functions compatible with this definition, from the six choices of P1, but since the distinction between P1 and its complement P2 only affects the overall sign of the function, we have a three-dimensional function space. It’s not hard to see that this representation is equivalent to the one we found for the 0-centres, since we can construct an isomorphism between them by identifying the functions that correspond to the same choices for P1.
For the angular velocities of the bearings at the 2-centres (which have coordinates (±1,±1,0,0) and permutations thereof), our function returns a zero vector if the two non-zero coordinates both lie in the same Pi. Otherwise, it returns another 2-centre orthogonal to the first by multiplying the non-zero coordinate that lies in P1 by 1 and the one that lies in P2 by –1. Again, we have an invariant three-dimensional function space with a representation that is equivalent to those for the 0-centres and 1-centres.
If we evaluate the three basis functions for a fixed 2-centre, say (1,1,0,0), the choices P1={1,2}, {1,3} and {1,4} give results (0,0,0,0), (1,–1,0,0) and (1,–1,0,0) again, which span a 1-dimensional space. The plane spanned by the 2-centre (1,1,0,0) and the angular velocity vector (1,–1,0,0) contains the 3-centres (1,0,0,0) and (0,1,0,0), which are precisely the ones whose bearings make contact with the one at (1,1,0,0). This means that the points of contact between those bearings will be poles for the rotation of the 2-centre bearings, and the 3-centre bearings can be motionless.
The 9-dimensional space comprising all linear combinations of the angular velocities we have derived for the 0-centres, 1-centres and 2-centres is then subject to the usual constraints: all the linear velocities at the points of contact must agree. But rather than having to express this individually for the 416 coordinates of the velocity differences at 208 points of contact, there is a 6-dimensional space (consisting of two three-dimensional irreps) in which the velocity differences must lie, and we can express the constraints in terms of those six degrees of freedom alone.
In constructing basis functions from points of contact to velocity differences, rather than choosing to partition the four coordinates into pairs, we will choose a cyclic order for the coordinates. There are six possible cyclic orders: 4!/4.
The first irrep we’ll describe lies in the space of linear velocity differences at points of contact between bearings at 0-centres and bearings at 1-centres. The velocity differences are true vectors, rather than pseudovectors, and they will be orthogonal to the vectors from the centre of the 3-sphere to both bearing centres. Given the centre of an edge and one of its vertices, the vector the function returns is chosen by negating the “next” coordinate of the edge centre after its sole zero coordinate (using the cyclic order), setting to zero the coordinate after that (again using the cyclic order), and then multiplying the result by the product of all the vertex coordinates. For example, if the cyclic order is {1,2,3,4}, the vertex is (1,1,1,1) and the edge centre is (0,1,1,1), then the function returns (0,–1,0,1).
If we reverse the cyclic order in our example, we get (0,1,0,–1) instead; the position of the zeroed coordinate is unchanged, while the negated and un-negated coordinates change place. So reversing the cyclic order always negates the function’s value. This means we have a space spanned by three functions, as we require.
Next, we construct functions for velocity differences at points of contact between bearings at 1-centres and bearings at 2-centres. Given an edge centre and a 2-face centre, the vector the function returns will be zero at every coordinate where the edge centre is non-zero. For the sole coordinate where the edge centre is zero, the vector returned is initially either –1, 0 or 1 depending on whether the second zero coordinate of the 2-face centre (that is, the one it doesn’t share with the edge centre) lies 1, 2 or 3 steps after the first in the cyclic order, but then we multiply the result by the product of the non-zero coordinates in the edge centre. For example, if the cyclic order is {1,2,3,4}, the edge centre is (0,1,1,1) and the 2-face centre is (0,0,1,1), the function returns (–1,0,0,0).
Again, reversing the cyclic order negates the function’s value, so we have a space spanned by three functions.
If the bearings in our system are rotating in any fashion described by the 9-dimensional space of angular velocities that transform according to the particular irrep we are using, Schur’s lemma tells us that it’s impossible for any velocity differences at the points of contact to lie outside the 6-dimensional space in which they transform according to the same irrep! So any constraints that are imposed on velocity differences outside this space would be redundant.
The kernel of our constraint operator L restricted to this 9-dimensional domain will be an invariant subspace of the domain under the 3-dimensional representation that applies here, so it must have dimension 0, 3, 6 or 9. But since L maps into a 6-dimensional space, the kernel must be at least 3-dimensional.
If we remove the complication of our specific choice of radii by working with variables ri ωi rather than ωi, and if we use basis functions derived from the recipes given above (and the function values normalised to unit vectors), with choices P1={1,2}, {1,3} and {1,4} in the domain and cyclic orders {1,4,2,3}, {1,2,3,4} and {1,3,4,2} in the codomain, we end up with a 6 × 9 matrix that can be written in block-matrix form as:
(1/√6) I3 (–½) I3 03 03 (½) I3 (1/√3) I3
Here I3 is the 3 × 3 identity matrix and 03 is the 3 × 3 zero matrix. The 2 × 3 matrix of coefficients of the identity matrix is:
1/√6 –½ 0 0 ½ 1/√3
This matrix has a one-dimensional kernel, spanned by (√2, 2/√3, –1). It follows that the original matrix has a three-dimensional kernel, spanned by (√2, 0, 0, 2/√3, 0, 0, –1, 0, 0), (0, √2, 0, 0, 2/√3, 0, 0, –1, 0) and (0, 0, √2, 0, 0, 2/√3, 0, 0, –1). Any linear combination of these three vectors will be a solution.
We can perform a kind of “spot check” on these results fairly easily. Suppose we pick a vertex, (1,1,1,1)/2, a neighbouring edge centre (0,1,1,1)/√3, and a neighbouring 2-centre, (0,0,1,1)/√2. We will look at the angular velocities we get from the basis functions for P1={1,3}. These are normalised to unit vectors, and assumed to be weighted by radius; we give them first as four-dimensional vectors, then as three-dimensional vectors when mapped to the purely imaginary tangent space at the identity:
Bearing centre ci Weighted angular velocity ri ωi(4)
from basis functionsri ωi(3) = ci* ri ωi(4) 0-centre (1,1,1,1)/2 (–1,1,–1,1)/2 (0,0,1) 1-centre (0,1,1,1)/√3 (0,–1,2,–1)/√6 (1,0,–1)/√2 2-centre (0,0,1,1)/√2 (0,0,1,–1)/√2 (1,0,0)
The edge vectors that apply in S3 are given by:
ei, j = Im(ci* cj) / |Im(ci* cj)|
which work out to be (we will write these as 3-dimensional, as they are purely imaginary):
e0,1 = (1,1,1)/√3
e1,2 = (0,1,–1)/√2
The appropriate constraint equations are:
ci [ri ωi(3) × ei, j] = –cj [rj ωj(3) × ei, j]
For arbitrary multiples of angular velocities from the basis functions, say α, β, γ, we have:
c0 [r0 ω0(3) × e0,1] = –c1 [r1 ω1(3) × e0,1]
(1,1,1,1)/2 [α (0,0,1) × (1,1,1)/√3] = –(0,1,1,1)/√3 [β (1,0,–1)/√2 × (1,1,1)/√3]
α (0, –1, 0, 1)/√3 = β (0, –1, 0, 1)/√2
and for the second point of contact:
c1 [r1 ω1(3) × e1,2] = –c2 [r2 ω2(3) × e1,2]
(0,1,1,1)/√3 [β (1,0,–1)/√2 × (0,1,–1)/√2] = –(0,0,1,1)/√2 [γ (1,0,0) × (0,1,–1)/√2]
β (–[√3]/2, 0, 0, 0) = γ (1, 0, 0, 0)
It’s easy to see that these constraints are satisfied by (α, β γ) equal to any multiple of (√2, 2/√3, –1), which we gave previously as the vector spanning the kernel of the 3 × 2 matrix.
With enough effort, we can always find bases such that the constraints operator L, when restricted to the isotypic subspaces that transform under the irrep dim ρi, has a matrix consisting of (dim ρi) × (dim ρi) blocks that are multiples of Idim ρi. In some cases, the projections into the isotypic subspaces will, for each subspace concerned solely with one kind of k-centre or one kind of contact point, project into a single irreducible subspace. But in other cases things are trickier, because the smallest isotypic subspace we reach still contains more than one copy of the irreducible representation.
When that happens, one thing we can do is take the representation on the isotypic subspace and apply what is known as the “Meat-Axe Algorithm”.[3][4] A nice introduction to this algorithm can be found on-line in [5], but we won’t go into the details here.
Another approach is to try to find a linear operator that commutes with the representation and that might have different eigenvalues on the isotypic subspace. Each eigenspace of such an operator for a given eigenvalue will be an invariant subspace. One example would be to take an operator that is similar to the Laplacian matrix for the graph of (say) nearest-neighbour relationships for the k-centres or the points of contact. The Laplacian matrix for a graph has rows and columns representing vertices of the graph, with an entry of –1 for any pair of vertices that are joined by an edge, and diagonal entries for each vertex equal to the degree of the vertex (the number of edges incident on it). Because we are dealing with a vector at each point rather than a scalar quantity, we could use an operator that takes, for example, the angular velocity vectors at the nearest neighbours to each k-centre, adds them all together, and then projects the result into the tangent space for that k-centre. (Whether or not we include the original angular velocity at that k-centre is a moot point, because that just amounts to adding the identity matrix to the operator, which merely increases all the eigenvalues by 1 without changing anything else.) The eigenspaces of this operator will be invariant: if the sum of every bearing’s neighbours’ angular velocities are equal to some multiple of the bearing’s own angular velocity, that multiple won’t change when we rotate or reflect the whole solution. There is no guarantee that these eigenspaces will split any given isotypic space, but there are a number of similar operators we can try.
So, one way or another, given an isotypic subspace we can always find bases that split it into irreducible subspaces. Relative to these bases, the constraints matrix will have submatrices of dimension (dim ρi) × (dim ρi), each of which is either zero, or describes an isomorphism between irreducible subspaces where the subrepresentation is equivalent to ρi. However, we might then need to do a bit more work to turn all these submatrices into multiples of the identity matrix.
Let’s give the irreducible subspaces of V240 that are copies of one particular irrep the names Va, Vb, Vc, etc., and those of V416 the names Wa, Wb, Wc, etc. If we pick any basis for Va, we can use the isomorphisms we get from restricting L to Va and projecting into Wa, Wb, Wc, ... to transfer that basis to some or all of the latter (in some cases we might get zero maps rather than isomorphisms). With such a choice of bases, the submatrices involving Va will all become identity matrices or zero matrices. We can then use the inverses of other isomorphisms to transfer the bases back from Wa to some or all of Vb, Vc, ..., again turning the corresponding submatrices into identity matrices.
Assuming for the sake of simplicity that we have encountered no gaps due to zero maps, what will happen to the other submatrices: say, the one that describes the isomorphism from Vb to Wb? We have already given Vb a basis by going from Va to Wa and from Wa to Vb, and we have already given Wb a basis by going from Va to Wb. In effect, we are already treating both Vb and Wb as isomorphic to Va. This latest isomorphism, directly from Vb to Wb, can thus be seen as an isomorphism from Va to Va. But then, according to the corollary to Schur’s lemma, in those terms it will necessarily be a scalar multiple of the identity matrix – and the way we have chosen our bases means that it is how it will appear here.
Given that our matrix is composed of submatrices that are all scalar multiples of the identity matrix Idim ρi, we can effectively divide its dimensions by dim ρi and consider the smaller matrix whose entries are the corresponding scalars. Having found the kernel of that matrix, we can reconstruct the larger kernel of the full matrix.
The second isotypic subspace comes from one of the group’s four-dimensional irreps. In fact, it is the fundamental pseudovector irrep, in which each matrix of the fundamental representation is multiplied by its determinant, adding an extra change of sign to any symmetry that includes a reflection. The entire subspace (before we solve for the constraints) is 24-dimensional, containing one copy of the irrep for the 0-centres and 3-centres, and two copies each for the 1-centres and 2-centres.
This time, all our basis functions can be identified with the choice of a particular coordinate, c. The four basis functions that give angular velocities from the coordinates of the 0-centres simply project the cth element of the standard basis for R4 (which has 1 for coordinate c and 0 for the rest) into the tangent space at the 0-centre. The four projected vectors all lie at equal angles from each other in the tangent space, forming the vertices of a regular tetrahedron.
Similarly, for the 3-centres the cth function projects the cth element of the standard basis into the tangent space at the 3-centre. This leaves the basis element unchanged unless it is parallel to the 3-centre, in which case the result is the zero vector.
For the 2-centres, the 4-dimensional irrep appears twice. For the first set of basis functions, if the cth coordinate of the 2-centre is zero, the function returns a zero vector. Otherwise, it projects the cth element of the standard basis into the tangent space at the 2-centre. If the result is not the zero vector, it will always be a multiple of a 2-centre, with two non-zero coordinates in the same position as the argument. For example, if c=1 and the 2-centre is (1,1,0,0)/√2 [taking care to express this as a unit vector], the projection of (1,0,0,0) into the tangent space is:
(1,0,0,0) – [(1,0,0,0) · (1,1,0,0)/√2] (1,1,0,0)/√2
= (1,0,0,0) – ½ (1,1,0,0)
= ½ (1,–1,0,0)
For the second set of functions, if the cth coordinate of the 2-centre is non-zero, the function returns a zero vector. Otherwise, it performs the same projection of the cth basis element. But this time, if the result is non-zero it will always be the original basis element, unchanged, since the condition guarantees that it is already orthogonal to the 2-centre.
For the 1-centres, the 4-dimensional irrep also appears twice, and we can use exactly the same definitions for the two sets of functions as we did for the 2-centres, with the result being the zero vector if the cth coordinate of the 1-centre is / is not zero, and the projection of the cth element of the standard basis into the tangent space at the 1-centre otherwise. For the second set of functions, the non-zero results are again the basis elements unchanged. For the first set of functions, the non-zero results will have three non-zero coordinates, but they won’t be multiples of any 1-centre. For example, if c=1 and the 1-centre is (1,1,1,0)/√3, we have for the projection:
(1,0,0,0) – [(1,0,0,0) · (1,1,1,0)/√3] (1,1,1,0)/√3
= (1,0,0,0) – ⅓ (1,1,1,0)
= ⅓ (2,–1,–1,0)
That covers the 24 angular velocity degrees of freedom that transform according to this particular irrep. For the velocity differences at the points of contact, we have a 16-dimensional space containing one copy of the irrep for the 0-centre/1-centre contacts and one for the 2-centre/3-centre contacts, and two copies of the irrep for the 1-centre/2-centre contacts.
As before, when switching from the angular velocity functions to the velocity differences, we need to use a different structure on the coordinates. Rather than simply choosing one coordinate, we will choose a set of three coordinates, and also endow that set with a cyclic order. There are four ways we can choose a subset of three coordinates (simply by choosing which coordinate to omit), and then two distinct cyclic orders we can impose on that set. For example, if we choose the set {1,2,3}, the six permutations of the set split up into two classes: {1,2,3}, {2,3,1} and {3,1,2}, giving one cyclic order, and {3,2,1}, {2,1,3} and {1,3,2}, giving the other. All our functions will be defined so that reversing the cyclic order negates the function’s value, so the eight choices we can make always generate four functions and their opposites.
For the 0-centre/1-centre contacts, the function returns a zero vector if the chosen coordinate triple coincides exactly with the 1-centre’s three non-zero coordinates. Otherwise, the result is produced by taking the 1-centre, setting the coordinate omitted from the triple to zero (meaning the result has two zeroes), negating the coordinate that follows the original zero (according to the cyclic order), and finally multiplying everything by the product of the signs of the 0-centre coordinates that belong to the chosen triple. For example, if we have chosen {1,2,3} as the cyclically ordered triple, and our vertex and edge centres are (1,1,–1,–1) and (0,1,–1,–1), we don’t have a zero result because coordinate 1, including in the triple, is zero. Instead, we generate a result as follows, step by step:
(0,1,–1,–1) → [zero the coordinate omitted from the triple] → (0,1,–1,0)
→ [negate the coordinate following original zero] → (0,–1,–1,0)
→ [multiply by product of signs of the vertex (1,1,–1,–1) from within the triple] → (0,1,1,0)
For the 2-centre/3-centre contacts, if the 2-centre is non-zero at the coordinate omitted from the triple, the result is a zero vector. Otherwise, the 2-centre is zero at the omitted coordinate and one other coordinate, which we will call p, and which lies within the triple. We will call the sole coordinate where the 3-centre is non-zero n; note that n must lie within the triple, since the 2-centre must also be non-zero at n. The result is a vector that is zero everywhere but coordinate p, where it is ±1. The particular sign comes from the product of the non-zero coordinates of the 2-centre, and a sign that is 1 or – depending on whether n comes straight after p or not, cyclically in the triple. [That’s complicated! It’s possible that there’s a simpler description that I’ve missed.] For example, if we have {1,2,3} as the triple, (–1,1,0,0) as the 2-centre and (–1,0,0,0) as the 3-centre, then p=3 and n=1, and the result is (0,0,–1,0).
For the first basis for the 1-centre/2-centre contacts, if the 1-centre is non-zero at the omitted coordinate, the function returns a zero vector. Otherwise, the result is given by taking the 2-centre, negating the coordinate that precedes (according to the triple) the position of its zero coordinate that lies within the triple, and multiplying everything by the product of the non-zero signs of the 1-centre. For example, if we have {1,2,3} as the triple, (1,1,1,0) as the 1-centre and (1,1,0,0) as the 2-centre, the 2-centre is zero at coordinate 3 within the triple, so we negate coordinate 2 and multiply by the product of signs, 1, to get a result of (1,–1,0,0).
For the second basis for the 1-centre/2-centre contacts, if the 2-centre is zero at the omitted coordinate, the result is a zero vector. Otherwise, let p be the position of the sole zero in the 1-centre, and q be the position of the other zero in the 2-centre. Both must belong to the triple, since the omitted coordinate is non-zero. The result is a vector that is zero only at coordinate p, and its sign is a product of the non-zero signs of the 1-centre from the coordinates in the triple and a sign that is 1 or –1 depending on whether p does or does not come straight after q in the triple. For example, if the triple is {1,2,3}, the 1-centre is (0,1,1,1) and the 2-centre is (0,0,1,1), then p=1, q=2, and p does not follow q in the triple. So the result is (–1,0,0,0).
Once again, with a suitable choice of bases the restricted constraints matrix takes a block-matrix form. For the angular velocities, we simply choose c=1,2,3 and 4. For the contact velocities, we use the triples {4,3,2}, {1,3,4}, {4,2,1} and {1,2,3}. The pattern here is that we omit 1, 2, 3 and 4 from the four coordinates to obtain the triple, and we alternate between descending and ascending order.
With this choice of bases, the matrix is:
⅓√2 I4 ½ I4 04 04 04 04 04 04 (–1/√3) I4 04 (–1/√3) I4 04 04 –½ I4 04 (–1/√3) I4 04 04 04 04 04 04 (–1/√2) I4 (–1/√2) I4
The 4 × 6 matrix obtained from the coefficients of I4 here has a two-dimensional kernel, spanned by the vectors (√[3/2], –2/√3, 0, 1, 0, 0) and (0, 0, 1, 0, –1, 1). So the original matrix has an 8-dimensional kernel within the 24-dimensional isotypic subspace, spanned by vectors where every coordinate is replaced by its own value multiplied by (1,0,0,0), (0,1,0,0), (0,0,1,0) or (0,0,0,1) in turn.

Geometrically, we can describe the eight solutions from the 4-dimensional irrep as follows. The first four (black arrows and numbers 1–4 in the image on the right) have non-zero angular velocities at all the vertices, but zero velocities at all the 3-centres. The four solutions give the bearings at the vertices angular velocities that form a regular tetradehron in each vertex’s tangent space, while 8 of the 32 bearings at edge-centres are motionless, as are 12 of the 24 bearings at 2-centres.
The second set of four solutions (blue arrows and numbers 5–8 in the image on the right) have zero angular velocities at the vertices, and non-zero angular velocities at most of the 3-centres. Each one of the four solutions sets the angular velocity of a pair of 3-centres to zero, while setting the others’ to one of the three coordinate directions that lie in their tangent space. This time, 24 of the 32 bearings at edge-centres are motionless for each solution, along with 12 of the 24 at 2-centres; these subsets of motionless bearings in the first four and second four solutions complement each other.
The three solutions from the 3-dimensional irrep (red arrows and numbers 9–11 in the image on the right) assign angular velocities to the bearings at the vertices that point towards mutually perpendicular edge-centres of the regular tetrahedron in the tangent space. These solutions assign non-zero angular velocities to all the 1-centres of the 4-cube, while 8 of the 24 2-centres and all the 3-centres are motionless.
The methods we have described for decomposing representations on large vector spaces into irreps are easy to apply to our example based on the 4-cube, but for systems with many more bearings, and symmetry groups containing many more elements, the sizes of some of the matrices required, and the number of operations that need to be performed on them, can grow to the point where the computations are no longer very practical.
For example, a system with a bearing at every vertex and every edge-centre of a 120-cell (a 4-dimensional polytope with 600 vertices, 1200 edges, 720 pentagonal faces and 120 dodecahedral cells) has a symmetry group known as H4, with 14,400 elements. The representations on the space of angular velocities at the vertices involve matrices of size 1800 × 1800, and the projection operators into the isotypic subspaces are constructed by summing such matrices over all 14,400 symmetries. For the other spaces, the dimensions are even larger.
The projection operators can be constructed knowing nothing more than the original representation’s matrices and the characters of the irreps. However, if we are able to create matrices for the irreps, there is another approach we can take, which gives us bases for the irreps within the large spaces without having to deal with so many large matrices. What’s more, we won’t need the irrep matrices for every element of the symmetry group, but only for a certain subset.
In order to understand this new approach, we need to view the original representations slightly differently. Taking the example of angular velocities at a set of vertices, we can ask: what is the subgroup of the overall symmetry group G that leaves one of the vertices fixed? For example, of all the rotations and reflections of the 4-cube with vertices (±1, ±1, ±1, ±1), which ones leave the vertex (1,1,1,1) unchanged? In this case, the subgroup has 24 elements. If we call this subgroup H, the action of H on the tangent space at (1,1,1,1) that it inherits from the representation ρPseudo of the larger group corresponds to the 24 rotational symmetries (without reflections) of an ordinary 3-dimensional cube.
Having identified this subgroup and its representation on the tangent space, we can imagine turning the whole process around: given any group G, any subgroup H of G, and any representation ρV of the subgroup H on some vector space V, we can construct a representation of the full group G that is known as an induced representation. In this construction, we identify the left cosets of H within the group G, and associate a copy of V with each one of them. In our own example, there are 16 cosets, and they consist of elements of G that take the vertex (1,1,1,1) to each of the 16 vertices of the 4-cube. The total vector space on which the induced representation acts is the direct sum of all the copies of V, which we will write as:
VInduced = ⊕i Vi
where by Vi we mean the copy of V associated with coset i. A given element of G acts by both permuting the copies of V and by acting within each copy with the original representation of H. To be more precise, we pick an element xi that belongs to each coset, and then having made that choice, given a generic element g of the group we will have a unique way of writing g xi for each i as:
g xi = xji hg, i
where the hg, i are all in H. For each i the product g xi must lie in some definite coset, coset ji, which means that we can write it as a product of our chosen element of that coset, xji, and a uniquely determined element of H, namely hg, i = xji–1 g xi. The induced representation then acts on a vector vi that lies wholly in Vi by mapping it to the vector ρV(hg, i) vi in Vji. To find the action on a completely general vector that might have components in several different Vi, we simply use linearity and add up the vectors we obtain from each such component:
ρInduced(g)(⊕i vi) = ⊕ji ρV(hg, i) vi
So far, we have just re-described the representations we are using for the angular (or linear) velocities for each distinct type of bearing centre (or point of contact). But what makes this re-description worthwhile is a remarkable result of Frobenius, known as the Frobenius reciprocity theorem.[6] This theorem tells us that if we have a representation of G on some vector space W, and we restrict that representation of G to obtain a representation of a subgroup H, the space of G-intertwiners between W and the induced representation of G is isomorphic to the space of H-intertwiners between W and V, the original space on which H acts that we used to construct the induced representation of G.
Why is this useful? H is smaller than G, and V is smaller than VInduced. If we choose ρW to be an irrep of G, we can construct H-intertwiners from W to V, and then map them into G-intertwiners from W to the induced representation – giving us a way to find bases for each copy of the irrep within the induced representation. (Keep in mind that although ρW is an irrep of G, and it will give a representation of H on W, it generally won’t be an irreducible representation of H.)
In more detail, suppose S is any H-intertwiner from W to V: that is, any linear map between those vector spaces that commutes with the representations of H on each of them.
S: W → V
S ρW(h) = ρV(h) S
Here ρW is an irrep of the full group G, but for the purposes of this definition of S as an H-intertwiner, we are only allowed to apply it to elements of H.
From S, we can construct a G-intertwiner from W to the induced representation:
T: W → VInduced = ⊕i Vi
T = ⊕i S ρW(xi)–1
Here the direct sum is over all the copies of V associated with each coset of H, or in our original terms, associated with each distinct k-centre of the 4-cube for a given k. The xi are the chosen elements of each coset, or the elements that map one nominated k-centre to each of the others. So, T acts on a vector in W by applying the irrep to it for the inverse of each xi, then passing the result through S into the ith copy of V.
We can check that T really is a G-intertwiner, commuting with the representations of G on W and on VInduced:
ρInduced(g) T
= ⊕ji ρV(hg, i) S ρW(xi)–1
= ⊕ji S ρW(hg, i) ρW(xi)–1
= ⊕ji S ρW(hg, i xi–1)
= ⊕ji S ρW(xji–1 g xi xi–1)
= ⊕ji S ρW(xji–1) ρW(g)
= T ρW(g)
How do we get an intertwiner S from W to V in the first place? We can take any linear map M from W to V, and then average it over the subgroup H:
S = [1 / |H|] Σh∈H ρV(h) M ρW(h–1)
The space of all linear maps from W to V will have a basis given by the set of dim V × dim W matrices with a 1 in a single location and zeroes everywhere else. What Frobenius’s reciprocity theorem tells us is that if we project that entire basis down into the space of H-intertwiners, we will always end up with as many linearly independent intertwiners as we need in order to have a distinct intertwiner T from W for each copy of the irrep in VInduced. In practice, we won’t usually have to project every map in the basis, because we can tell from the inner product of the character of the induced representation and the character of the irrep how many copies there are, and stop the process when we have that many linearly independent intertwiners.
Given all the G-intertwiners T from W to the induced representation VInduced, we can simply map a basis of W into VInduced, giving us a basis for every copy of the irrep. The matrices for each T will be dim VInduced × dim W, rather than dim VInduced × dim VInduced, and we only need to sum over the coset representatives xi rather than every single element of the group.
The basis we get from each intertwiner will span a single, irreducible subspace in VInduced, so there is no more work needed to split the isotypic subspaces. What’s more, since we obtain our bases for all these irreducible subspaces by applying intertwiners to a single basis of W, the matrices Li that describe the restriction of L to each isotypic subspace will always be composed of irrep-sized blocks that are multiples of the identity.
As a further refinement, we can make the bases we get from each intertwiner span irreducible subspaces that are all mutually orthogonal (my thanks to Vít Tuček and Ben Webster, who explained how to do this in response to a question I asked on MathOverflow). We orthogonalise our basis of H-interwiners {S1, S2, ...} using the inner product:
<Si, Sj > = Tr Si† Sj
where by Si† we mean the Hermitian adjoint of Si, which corresponds to taking the conjugate transpose of the matrix for the intertwiner with respect to an orthonormal basis. The G-intertwiners {T1, T2, ...} that we obtain from the orthogonalised set of H-intertwiners will then also be orthogonal under the same kind of inner product. The operator Ti† Tj will be an intertwiner from W back to W, commuting with the irreducible representation on W, so by Schur’s lemma it will be a multiple of the identity. That means its trace will be zero if and only if the operator itself is equal to zero. From the relationship between the adjoint and the inner products on W and VInduced, we have:
< Ti x, Tj y > = < x, Ti† Tj y >
If i≠j then the right-hand side will be zero for all x, y ∈W, because Ti† Tj=0 for our orthogonalised basis. So the left-hand side, too, will always be zero, meaning Ti and Tj will map W into mutually orthogonal subspaces of VInduced.
This makes things much easier when it comes to finding the left inverses of the matrices containing the bases for the subspaces, because we can now compute them separately for each orthogonal subspace in the isotypic subspace, reducing the size of the matrices we have to invert.
In the previous section we mentioned the example of a system with a bearing at each of the 600 vertices and 1200 edge-centres of a 120-cell. The image above shows the projection down to three dimensions of 830 bearings out of the total of 1800: those that lie entirely on one side of a hyperplane through the origin. The bearings at the vertices are coloured red, and those at the edge-centres are coloured green. The grids on each bearing are aligned with the axis of rotation, with the particular spacings chosen to allow a finite number of images to repeat in a loop without a noticeable jump, although the exact periods of rotation are not rational multiples of each other.
The system of equations for the velocity differences between all 1800 bearings at their 2400 points of contact corresponds to a 4800 × 5400 matrix. H4, the symmetry group of the 120-cell, has 14,400 elements and 34 irreducible representations. But the subgroups of H4 that fix the relevant features of the 120-cell are much smaller:
After re-expressing the constraints in a basis adapted to the irreducible representations, and replacing multiples of the identity with scalars, the largest matrix that arises has dimensions of just 18 × 16 (due to one irrep of H4 that occurs 16 times in the space of angular velocities for the bearings, and 18 times in the space of linear velocity differences).
The solution space turns out to have a dimension of 1319, encompassing 27 of the irreps. There are some highly symmetrical solutions in which the bearings fall into a small number of groups that share the same rotational speeds, but in those cases either some of the bearings are stationary, or some of them make contact at their rotational poles. So the particular solution portrayed was chosen to be more or less generic, to illustrate clearly that such extra constraints are not necessary: all the bearings are in motion, and there are non-zero velocities at all points of contact.
The dimension of 1319 for the solution space can be easily understood in terms of ideas we have discussed previously. Generically, we would expect a dimension of 3 × 1800 – 2 × 2400 = 600. But our system of bearings contains 720 even, “planar” loops: one for each of the 720 pentagons in the 120-cell. Each such loop implies a linear relationship between the constraints. However, by symmetry the sum of all 720 linear relationships is zero, so there are only 719 independent ones. This leads to a total dimension for the solution space of 600 + 719 = 1319.
The technique described in the previous section, based on the Frobenius reciprocity theorem, relies on having matrices for all the irreps, for certain elements of H4: those that lie either in one of the three subgroups that fix a vertex, an edge-centre, or a point of contact, or those that are the chosen representatives of the left cosets of those subgroups. All in all, that comes to 2440 out of the 14,400 elements. I was able to find matrices for some irreps using a well known 2-to-1 homomorphism from SU(2)×SU(2) → SO(4), where SU(2) can be thought of as the group of all unit quaternions, and SO(4) is the group of all rotations of 4-dimensional space. (The construction for those infinite groups is described in some detail here.) This homomorphism restricts to a 2-to-1 map f from pairs of icosians (a finite group comprising 120 unit quaternions, which lie at the centres of the dodecahedral cells of the 120-cell) to the 7200 rotations in H4:
f(q1, q2) x = q1 x q2*
Here (q1, q2) is the pair of icosians, x is a vector in R4 construed as a quaternion, and the right-hand side of this definition uses quaternion multiplication. If we take the opposite of both icosians in the pair, (–q1, –q2), we will produce exactly the same rotation, which is why the homomorphism from pairs of icosians to H4 is 2-to-1 rather than 1-to-1.
Given two irreducible representatations of SU(2), say ρj and ρk on spaces Vj and Vk, we get a representation of the group of pairs of icosians on the tensor product Vj ⊗ Vk:
ρj, k(q1, q2) v ⊗ w = (ρj(q1) v) ⊗ (ρk(q2) w)
The irreps of SU(2) we are using are known as spin-j representations, because of their role in the quantum mechanics of angular momentum, and their labels come in integer and half-integer values 0, ½, 1, 3/2, 2, ... The dimension of the spin-j irrep is 2j+1. The half-integer irreps are called fermionic representations, and they have the property ρj(–q)=–ρj(q), while those with integer labels are called bosonic representations, with ρj(–q)=ρj(q).
What this means is that if j+k is an integer, ρj, k as we have defined it will not depend on whether we associate (q1, q2) or (–q1, –q2) with a particular rotation in H4. So for each such rotation, we get a unique linear operator on Vj ⊗ Vk.
H4 contains reflections as well as rotations, but we can extend our construction to include reflections. If we pick a certain reflection and call it P, when j=k we can represent P as:
ρj, j, p(P) v ⊗ w = p w ⊗ v
where p=±1 is another parameter of the representation that we are free to choose. We then obtain representations for all reflections by writing them as products of pure rotations and P, and composing the resulting linear operators.
For j≠k, we need to extend the representation to a larger space: the direct sum of Vj ⊗ Vk and Vk ⊗ Vj. We then define:
ρ(j, k)⊕(k, j), p(q1, q2) (s ⊗ t, v ⊗ w) = ((ρj(q1) s) ⊗ (ρk(q2) t), (ρk(q1) v) ⊗ (ρj(q2) w))
ρ(j, k)⊕(k, j), p(P) (s ⊗ t, v ⊗ w) = p (w ⊗ v, t ⊗ s)
There are an infinite number of choices for j and k, but this construction only gives irreps of H4 in 18 cases. Another eight can be found by algebraic conjugation of existing irreps: when the elements of the matrices are algebraic numbers of the form a + b √5, where a and b are rational, then the substitution √5 → –√5 will yield a new irrep. This might sound surprising at first, but like complex conjugation, algebraic conjugation commutes with addition and multiplication, and hence with matrix multiplication, so if the definining property of a representation, ρ(g h) = ρ(g) ρ(h), holds for one set of matrices, it will also hold for their algebraic conjugates.
The methods described so far yielded a total of 26 irreps. The characters of the remaining eight irreps were found by means of the Burnside-Dixon algorithm[7], and then matrices for the irreps were found by projecting them out of reducible representations on various function spaces (including the space of functions on the icosians, and the space of functions on the vertices of the 120-cell) in which they occurred only once.
So far, we’ve only looked closely at the situation in R3 and S3, which are atypical manifolds because they can be parallelised. What happens in more general manifolds where this is impossible?
Suppose we have an n-dimensional manifold M with a metric g. We can use the metric to define a Levi-Civita connection: a means of parallel-transporting tangent vectors that preserves their lengths and the angles between them, as measured by the manifold’s metric. The connection also lets us define geodesics, as curves whose tangents remain constant, in the sense that their covariant derivative with respect to the connection is zero.
We will say that there is a well-behaved sphere at point c in the manifold, with geodesic radius ρ and metric radius r, if the following conditions are met:
This sounds a bit abstract, but these conditions are certainly met by the manifold Sn, if we assume a unit radius for Sn, restrict ρ to be less than π, and set r = sin ρ. That is, if we travel a distance ρ along all the great circles that pass through a point c, we will arrive at a sphere around c whose geometry is that of a sphere in the tangent space (that is, in flat Euclidean space) of radius sin ρ.
We will describe the angular velocity of each ball bearing in terms of a linear operator on the tangent space, Ω: Tc→Tc, with g(Ω v, v) = 0 for all v in Tc. The operator Ω will have an antisymmetric matrix of coordinates in any orthonormal basis for the tangent space.
We can talk about the linear velocity of a point on the surface of the ball bearing as follows. Any point t on the surface of the bearing will be equal to G(v) for some v in Tc, with |v|=r. The point v can be thought of as having a linear velocity Ω v that lives in Tc, or since Tc is just a vector space that is isomorphic to all the tangent spaces at its own points, we can think of Ω v as living in Tv. The derivative map of G at v, which we will call G'(v), maps Tv to TG(v)=Tt, so G'(v)(Ω v) will be a vector in Tt, the tangent space at t.
Whatever the angular velocity, Ω, the condition g(Ω v, v) = 0 means that Ω v will always lie in an (n–1)-dimensional subspace of Tv normal to v, and G'(v)(Ω v) will lie in an (n–1)-dimensional subspace of Tt normal to G'(v)(v). This follows from a result about the exponential map known as Gauss’s lemma, which states that the derivative of the exponential map preserves the dot product between tangent vectors.
Now, suppose we have two bearings with centres ci and cj, geodesic radii ρi and ρj, metric radii ri and rj, and angular velocities Ωi and Ωj. And suppose they are tangent to each other, in the sense that there is a point in the manifold:
ti, j = Gi(vi) = Gj(vj)
that lies on a geodesic that joins ci to cj, for some vi in Tci with |vi|=ri and vj in Tcj with |vj|=rj. The subscripts on Gi and Gj are shorthand for saying that the c, ρ and r we used when previously defining G now need to be distinguished by the appropriate subscripts.
The contact condition for the linear velocities to agree is:
Gi'(vi)(Ωi vi) = Gj'(vj)(Ωj vj)


As well as finite collections of bearings, we can consider infinite lattices. One simple example is the lattice of spheres in R3 with their centres at integer coordinates. Because the set of integers are usually given the symbol Z, this lattice is known as Z3.
There is an obvious three-parameter space of solutions in which all the bearings rotate with the same speed:
ω(x, y, z) = (a (–1)y+z, b (–1)x+z, c (–1)x+y)
Here a, b and c are the parameters of the solution space. Every bearing makes contact with six others, which differ in one of the three coordinates by ±1. It’s not hard to check that a change in any coordinate by ±1 causes the components of ω(x, y, z) in the other two coordinates to change sign, which is enough to guarantee that the linear velocities of the bearings will agree at the point of contact.
Because all the bearings rotate with the same speed, they can be replaced by sets of circular gears, one for each circle of latitude on which a point of contact lies. The images above show two views of such a lattice of gears, with a solution where a=1, b=2, and c=3. The first movie is taken from a viewpoint that moves “down” through the lattice, while its gaze rotates through ninety degrees for every unit distance travelled. The second movie, taken from a fixed viewpoint, has two planes of the lattice stripped away to allow more of the gear systems to be visible.
One basis for the full solution space can be described as follows. Define:
ωk, m(x1, x2, x3) = (–1)x1+x2+x3+δm, xk ek
where k ∈ {1,2,3}, and m can be any integer, or ∞. The vector ek is the kth element of the standard basis for R3 (i.e. it has 1 as its kth coordinate and zeroes for the rest). The symbol δ here is the Kronecker delta, which equals one when its two subscripts have the same value, and zero otherwise.
For m=∞ the Kronecker delta is always zero, so we can write:
ωk, ∞(x1, x2, x3) = (–1)x1+x2+x3 ek
Clearly ωk, ∞ changes sign whenever any of the coordinates changes by ±1, and hence the angular velocities of neighbouring bearings are always opposites.
When m is finite, two neighbouring bearings separated in a direction other than the kth will again have opposite angular velocities. Two neighbours separated in the kth direction will have angular velocities that might not be opposites, but the angular velocities will be aligned with the edge joining the centres of the bearings, so the linear velocities at the point of contact between the bearings will both be zero.
The most common form for gears that lie flat in the same plane are involute gears, in which the sides of the teeth are involutes of a circle. If you imagine a string wrapped around a circle, if you take the free end of the string and begin to unwind it, keeping the string taut so that the portion that is unwrapped always forms a tangent to the circle, then the curve traced out by the end of the string is an involute. The great Swiss mathematician Leonhard Euler devised a gear based on this curve, in which the point of contact between two gears follows the same path as a point on a string that is being unwound from one circle and wound onto another. In this case, the point on the string simultaneously traces out two involutes that rotate along with the two circles, while the portion of the string that is temporarily unwrapped lies along a fixed line segment tangent to both circles.

We can repeat this whole construction on the surface of a sphere. The difference is that two circles on a sphere no longer lie in the same plane, and the unwrapped portion of the string follows a geodesic, or great circle, rather than a straight line.

Just as we can extend two-dimensional flat gears into three dimensions by treating them as a kind of cylinder, we can extend these spherical gears into three dimensions by treating them as a kind of truncated cone: each point on the spherical gear becomes a line segment that, if extended, would pass through the centre of the sphere.

The resulting form is known as a bevel gear, and it allows two gears to turn when they do not lie in the same plane, but their axes of rotation intersect. The sphere used to construct the gears is placed at the point of intersection of the axes, and the cones that are generated by the spherical gears can be sliced along any suitable planes.
For the spheres in the Z3 lattice (or indeed any three-dimensional spheres that make rolling contact) the circles traced out on each sphere by the point of contact must share a common tangent at that point, in order for the linear velocities to agree. This is enough to guarantee that the spheres’ axes of rotation will intersect.
For the lattice Zn in n dimensions, we can generalise our 3-dimensional subspace of solutions to a subspace of dimension ½n(n–1):
M(x) = Σj < k (–1)xj + xk aj, k ej ∧ ek
Here the symbol ∧ is a wedge product: an antisymmetric tensor product. What this means is that ej ∧ ek corresponds to a matrix with a 1 in the kth column of the jth row, a –1 in the jth column of the kth row, and zero elsewhere. The matrix product with an arbitrary basis vector is:
(ej ∧ ek) ei = δi, k ej – δi, j ek
For two neighbouring points whose coordinates differ by ±1 in the ith direction, we have:
(M(x) + M(x ± ei)) ei = (Σj < k (–1)xj + xk aj, k ej ∧ ek + Σj < k (–1)xj ± δi, j + xk ± δi, k aj, k ej ∧ ek ) ei
= (Σj < k [(–1)xj + xk + (–1)xj ± δi, j + xk ± δi, k ] aj, k) (δi, k ej – δi, j ek)
= δi, k (Σj < k [(–1)xj + xk + (–1)xj + xk ± 1 ] aj, k) ej – δi, j (Σj < k [(–1)xj + xk + (–1)xj ± 1 + xk ] aj, k) ek
= 0
This is exactly the condition we need for the linear velocities of the two neighbouring spheres at their point of contact, ±½ M(x) ei and –(±½) M(x ± ei) ei, to be equal.
For this family of solutions, the rotational velocities of all the spheres will have equal magnitudes, where we define the magnitude as the square root of the sum of the squares of the components of the matrix M. However, a rotation in n dimensions has a more complicated relationship between the magnitude of its rotational velocity and its period than is the case in three dimensions. If we define the period τ to be the shortest time after which the motion returns every point on the sphere to its original position, this amounts to asking for the smallest positive solution of the equation:
exp(τ M) = In
where the exp function here is the matrix exponential. While this equation always has a positive solution in 2 or 3 dimensions, in higher dimensions it might not have any non-zero solutions. However, we can always find a basis in which M takes the form of a number of simultaneous rotations in distinct planes, each with its own period τi. If we choose a basis of eigenvectors for the symmetric matrix M2, the eigenvalue of M2 in each eigenplane will be –ωi2, where ωi = 2 π / τi.
Suppose we have an eigenbasis {e1, f1, e2, f2, ..., g if n is odd} for M2, where ei and fi form an orthonormal basis for the ith eigenplane, and if n is odd there is an additional vector g that spans a one-dimensional subspace with an eigenvalue of zero. The trajectory of a generic point under rotation will be:
x(t) = Σi ri (cos (ωi t + φi) ei + sin (ωi t + φi) fi) [+ r0 g if n is odd]
where the ri and φi are constants that pick out the point at t=0. For n=3 there is only one eigenplane so the trajectory always forms a circle, but for higher n the trajectory will only form a closed curve if the various τi are rational multiples of each other.
If we impose appropriate conditions on the parameters aj, k, we can make all the periods equal. For example, for n=4 we can restrict the solutions to a 3-parameter subspace:
a2, 3 = a1, 4
a2, 4 = –a1, 3
a3, 4 = a1, 2
and we then have:
M(x)2 = –(a1, 22 + a1, 32 + a1, 42) I4
So the rotation as a whole has a well-defined period, τ = 2 π / √(a1, 22 + a1, 32 + a1, 42).
These conditions make the matrices M(x) for each sphere in the lattice alternately self-dual and anti-self-dual: that is, the act of swapping angular velocities in any of the coordinate planes for those in the orthogonal plane either leaves M unchanged, or simply inverts its sign. The concept of self-dual and anti-self-dual angular velocities only makes sense in four dimensions, but we can impose conditions in any number of dimensions that force all the rotational periods to be the same.
For the 3-parameter family of solutions in four dimensions, the rotations of each bearing carry the eight contact points around four distinct, non-intersecting great circles, and these circles are coplanar with the ones on neighbouring spheres that they touch. So it’s possible to set up structures along these circles that mesh at the contact points in much the same manner as flat gears. Just as the basic two-dimensional shape for a gear can be extended into a third dimension by replacing each point with a line segment, the same shape can be extended into four dimensions by replacing each point with a square that spans the two extra dimensions.
The image below shows a portion of a Z4 lattice (a 3 × 3 × 3 cube, with one dimension fixed) with a1, 2 = a1, 3 = a1, 4 = 1. The structures are projected down to three dimensions but given hues that vary according to the omitted fourth coordinate. Each hypersphere has four circular “gears” wrapped around it, but some of these project to straight line segments rather than circles or ellipses. Each gear that touches its neighbour at a contact point displaced from the centre of the hypersphere along the kth dimension forms part of a sequence of coplanar gears that rotate in alternating directions, but the plane associated with dimension k isn’t fixed, it changes its orientation when the other coordinates change.

[1] S. Steinberg, Group Theory and Physics, Cambridge University Press, 1994. Section 2.3.
[2] Steinberg, op. cit., Section 2.4.
[3] Parker, R. A. (Atkinson, M. D., Ed.), “The computer calculation of modular characters (the meat-axe)”, in Computational group theory (Durham, 1982), Academic Press, London (1984), 267–274.
[4] Derek Holt and Sarah Rees, “Testing modules for irreducibility”, J. Austral. Math. Soc. Ser. A, 57(1):1–16 (1994).
[5] Joseph Thomas, “Computational Approaches to Finding Irreducible Representations”, online at http://math.arizona.edu/~ura-reports/081/Thomas.Joseph/Final.pdf (PDF).
[6] Steinberg, op. cit., Section 3.3.
[7] Richard Thomas Bayley, “Implementing the Burnside-Dixon Algorithm in Gap”, online at http://www.maths.qmul.ac.uk/~rtb/mathpage/Richard%20Bayley's%20Homepage_files/Dixon.pdf (PDF).