A superpermutation[1] is a string formed from a set of n symbols such that every one of the n! permutations of those symbols appears at least once as a contiguous block of n characters in the string. The set of symbols can consist of anything at all, but for the sake of simplicity we will use decimal digits, starting from 1. To be clear, though, we are not discussing the representations of integers by digits in a particular base. For our purposes, these strings of digits are just strings of arbitrary symbols.
Here are some superpermutations, for n = 1, 2, and 3:
1
121
123121321
To make it a little easier to separate out the contiguous blocks, they have been marked here with various typographical features. So for n=3, it’s not too hard to read off all six permutations:
123, 231, 312, 213, 132 and 321.
In the last example, most of the characters are used as parts of two or three different permutations. Clearly we could build a superpermutation just by listing all the individual permutations, one after another with no overlap, but the interesting features of these strings revolve around finding systematic ways to construct them that yield significantly shorter results than that.
In the n=3 example, the length of the string is 9, so there are a total of 7 frames: contiguous blocks of n characters. That means one of the frames must not contain a permutation, and indeed, the fourth frame is 121, which contains two 1s and no 3, so it is not a permutation. For n≥3 it is unavoidable that some frames will be wasted.
Here are a couple more examples, for n=4 and n=5:
123412314231243121342132413214321
123451234152341253412354123145231425314235142315423124531243512431524312543121345213425134215342135421324513241532413524132541321453214352143251432154321
The lengths of the superpermutations we have exhibited so far for n = 1, 2, 3, 4, 5 are L(n) = 1, 3, 9, 33 and 153. You might notice that these all obey the equation:
L(n) = L(n–1) + n!
and in fact we have:
L(n) = 1! + 2! + ... + n!
This formula is a result of a simple recursive algorithm used to construct these examples, which I learned from an excellent overview of superpermutations by Nathaniel Johnston[1]. Given a superpermutation on n–1 symbols, to obtain one with n symbols you perform the following steps:
For example, to get from n=2 to n=3, we write:
121
12 | 21
12 3 12 | 21 3 21
123121321
and to get from n=3 to n=4, we write:
123121321
123 | 231 | 312 | 213 | 132 | 321
123 4 123 | 231 4 231 | 312 4 312 | 213 4 213 | 132 4 132 | 321 4 321
123412314231243121342132413214321
How can we be sure that the new string will contain every possible permutation of n symbols? If you take any permutation of n symbols and read off whatever comes after the n, in cyclic order, you will obtain a shorter permutation of n–1 symbols. For example, taking 15423 and reading after the 5 gives you 4231. There will be exactly n different longer permutations that give each particular shorter one; these are just rotations of the same sequence: 15423, 54231, 42315, 23154 and 31542. Conversely, if we take two copies of the shorter one, and put an n between them, then there will be n consecutive n-frames starting from the first which contain all the longer permutations associated with the shorter one: 4231 5 4231 contains 42315, 23154 etc. Since the algorithm we’ve described applies this to a list of all the shorter ones, in the end it will necessarily generate all the longer ones.
Why does this process always increase the length of the string by exactly n!? First, note that however many characters we gain when we unpack the L(n–1) characters of the original superpermutation into (n–1) × (n–1)! characters explicitly listing all the individual permutations, we will lose exactly the same number again when we squeeze the adjacent copies of those permutations back together again at the end. So the net gain comes from the duplication of those (n–1) × (n–1)! characters, plus the (n–1)! copies of the new symbol, n. So the gain is:
(n–1) × (n–1)! + (n–1)! = n!
We have a simple algorithm that is guaranteed to generate superpermutations for any n, and a simple formula telling us the length of those superpermutations:
L(n) = 1! + 2! + ... + n!
So, one natural question to ask is whether it’s possible to do any better than this. For n=1,2,3,4 it is not too hard to check, with some computer assistance, that the recursive algorithm yields superpermutations that are as short as possible, and that are unique up to an overall renumbering of the digits. So does it always yield a superpermutation of the minimum possible length for each n?
For about twenty years, no one had any counterexamples to this plausible-sounding conjecture. But from 2013, some cracks began to appear. First, Nathaniel Johnston showed[2] that for n≥5, superpermutations of the same length as that produced by the algorithm could not be unique: there would be an increasingly large amount of freedom to renumber some parts of the string independently of others, without changing the length.
In 2014, Ben Chaffin found[3], after an exhaustive computer search, that although there were no shorter superpermutations for n=5, there were a total of 8 different ones of the same length. And while the recursive algorithm always generated strings with wasted characters placed in a certain pattern, 6 of Chaffin’s 8 superpermutations deviated from that pattern, despite retaining the same overall length.
Very soon after Chaffin’s result, Robin Houston announced[4] the discovery of a superpermutation for n=6 with only 872 characters, one less than L(6)=873. He found this by treating the construction of superpermutations as an example of the Travelling Salesman Problem, and using algorithms designed to generate solutions to that problem. So the original minimal superpermutation conjecture was proved false!
By applying the usual recursion to Houston’s shorter n=6 superpermutations, it becomes possible to generate superpermutations for any greater value of n that are also one character shorter than L(n).
However, it turns out that for n≥7, there is a way to do even better. By adapting a construction devised by Aaron Williams[5] in 2013, it’s possible to generate superpermutations of length:
L2(n) = n! + (n–1)! + (n–2)! + (n–3)! + n – 3
This construction only works for n>3, and for n < 6 it produces longer strings than the standard algorithm. But at n=6 it produces strings of equal length (but a different structure) than the standard algorithm, and for n≥7, it yields strings that are shorter than the standard ones by an increasing margin:
You can see examples of these superpermutations here:
Shorter superpermutations than those produced by either the standard algorithm or this new construction are currently known only for two specific cases:
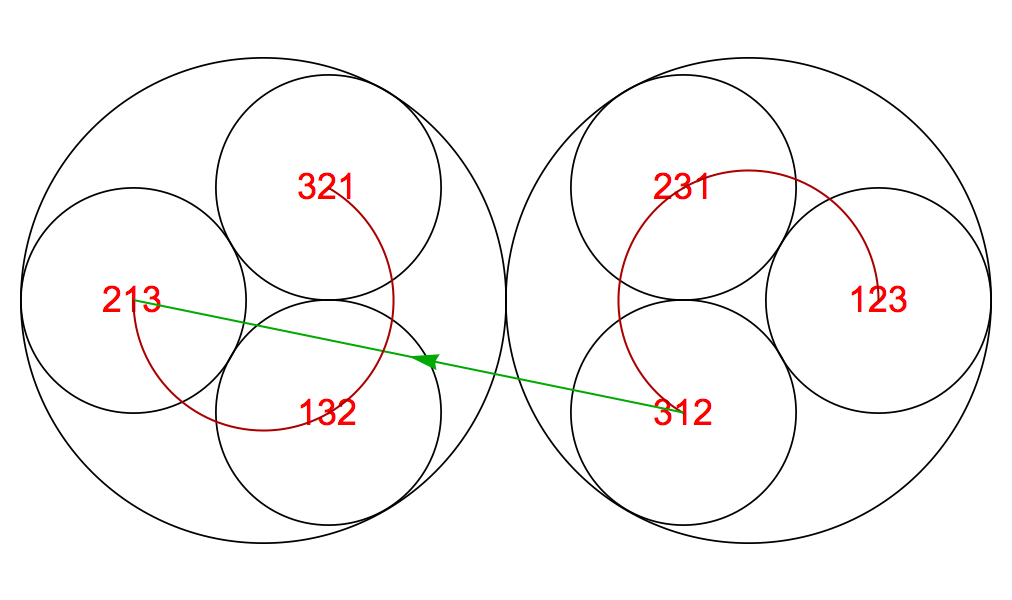
To understand both Robin Houston’s methods and the Williams construction, we need to think of the set of permutations for a given n as a kind of graph. In this graph, each permutation is a vertex, and (at least to start with) there is a directed edge joining every permutation to every other permutation. Associated with each edge is a weight given by the least number of characters we can append to the first permutation (and then drop from the start) in order to change it into the second permutation.
For example, for n=3, if we start with 123, we can ask how it can be turned into each of the other five permutations:
Weights like this quantify the number of characters we need to add as we build up a superpermutation by starting at one vertex in the graph and then visiting all the other vertices, preferably with the shortest possible total weight. A path through a graph that visits each vertex exactly once is known as a Hamiltonian path, and the problem of finding a Hamiltonian path through a directed graph that minimises the total weight of all the edges traversed is a variation of the Travelling Salesman Problem.
One immediate simplification we can make is to remove edges, like the one from 123 to 312, that involve adding two or more characters such that we pass through another permutation along the way. As soon as we add 1 after 123, we have 231, so it would make no sense in terms of a superpermutation to think of bypassing 231 and going straight from 123 to 312. We will describe edges like this as improper, and in everything that follows we will assume that they have been excluded from the graph.
Having taken away the improper edges, every vertex will have exactly one weight-1 edge and one weight-2 edge leaving it, and also exactly one weight-1 edge and one weight-2 edge reaching it.
Robin Houston found the superpermutations of length 872 for n=6 by setting up a graph like this, and then searching for low-weight Hamiltonian paths using software dedicated to that problem. There are some technical issues regarding the kind of graphs and paths that different programs deal with, which you can read about in his paper[4].
The standard, recursive algorithm finds a path through these graphs that is endowed with a highly regular, recursive structure.
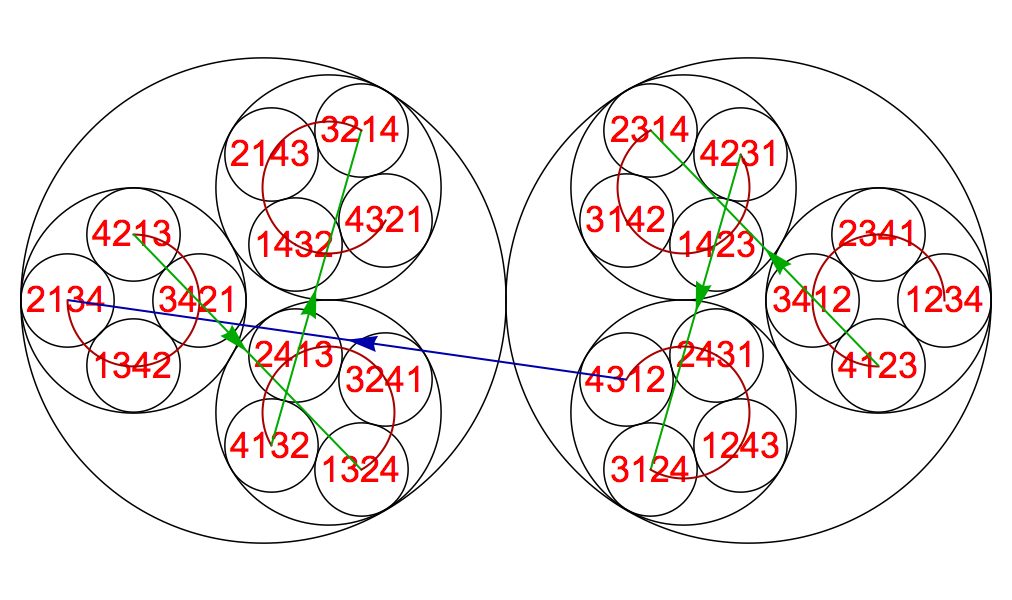

In the images above, we have omitted arrows on the weight-1 edges, which are the red circular arcs; these are always traversed counterclockwise. And we have omitted labels for the permutations for n=5, to avoid clutter. In the standard construction, we always have (so long as the weights mentioned are positive):
When we apply the recursive construction to obtain a new superpermutation with n increased by 1, all the edges in the original path have their weight increased by 1, and the new weight-1 edges link those permutations that are all descended from the same lower-order permutation.
To adapt the work by Aaron Williams on Hamiltonian paths through the symmetric group[5] to the problem of constructing superpermutations, we need to pare down the graphs so they only contain edges of weight 1 and weight 2.
In the languge of group theory, the set of permutations of n objects is known as the symmetric group on n letters, Sn. There are a few different ways to think about the multiplication of elements of this group, but we will adopt the following: we will take the permutation 123...n to be the identity of the group, and we will treat any permutation with the digits in a different order as a function that takes one ordered n-tuple and spits out a new n-tuple containing the same entries as the first, but rearranged in the new order. So by 52314, we mean a function that, when fed any (p1, p2, p3, p4, p5), gives the result (p5, p2, p3, p1, p4). When we multiply one permutation by another on the right, we compose these functions, with the rightmost one applied last.
When we move from a permutation to its successor along a weight-1 edge, that amounts to multiplying the original permutation by the permutation 2345...n1, which simply rotates everything one place to the left. We will call this permutation σ.
When we move from a permutation to its successor along a weight-2 edge, that amounts to multiplying the original permutation by the permutation 345...n21, which rotates everything two places to the left, and then swaps the order of the two entries that it moved from the start to the end. We will call this permutation δ.
It turns out that these two permutations are enough to generate the whole group: every element can be written as some product built up from these two (or the empty product, which is just the identity). So any g in Sn can be written in a form like σ σ δ σ ... with some finite number of terms. This means we can certainly reach every permutation, starting from the identity, using only weight-1 and weight-2 edges. However, that is not enough to guarantee that we can find a Hamiltonian path, which needs to visit each permutation exactly once.
Williams[5] proved that the graph on the symmetric group generated by a slightly different pair of permutations is Hamiltonian. He called his permutations σ and τ, and as you might guess, we have chosen to call the weight-1 edge permutation σ because it is exactly the same as Williams’s σ. But his τ is the permutation 21345...n that transposes the first two entries. The good news is that most of the beautiful work that Williams has done with his choice of permutations can be adapted, without much trouble, to use our permutations σ and δ instead.
To explicitly construct a Hamiltonian path through the symmetric group, Williams first proves that you can construct a cycle cover of the group that consists of just two cycles, which can then be cut and spliced to form a path that visits each vertex once.
A cycle cover is a set of disjoint loops through the graph, such that every vertex belongs to exactly one loop. Given a cycle cover, every vertex is assigned exactly one edge that reaches it, and exactly one edge that leaves it. In fact, if you just supply a list of directed edges and forget which cycles they came from, that is enough information to reconstruct the cycles themselves, because you can start at any vertex, follow the edges until you get back where you began, and if there are any unused edges you repeat the process until you are done.
One simple example of a cycle cover in our graph is the one containing all the weight-1 edges. Since every vertex has one weight-1 edge reaching it and one leaving it, we can just following these edges around in loops. Each loop will contain n vertices, and there will be (n–1)! such loops. We will call these loops, comprised solely of weight-1 edges, 1-cycles.
To construct his cycle covers, Williams starts with a structure he calls an alternating cycle. Our version of this will be as follows: take any vertex, and then repeatedly multiply by δ, then σ–1, then δ, then σ–1 ... until you loop back to where you started. This corresponds to the recipe: follow a weight-2 edge, then a weight-1 edge backwards, and repeat until you return to your starting point. That might sound a bit shocking in the context of a directed graph, like driving the wrong way up a one-way street, but don’t worry, this is just a kind of temporary roadworks that will be dismantled once it serves its purpose.
In concrete terms, the combined permutation δ σ–1 = 1345...n2 just performs a left rotation on the last n–1 entries, leaving the first unmoved. This means that applying it repeatedly will take you back where you started after n–1 steps, but because we are including the vertices produced when multiplying by δ alone, we produce loops of size 2(n–1). For example, starting at 12345, we obtain the alternating cycle:
12345 × δ ⇒ 34521 × σ–1 ←
13452 × δ ⇒ 45231 × σ–1 ←
14523 × δ ⇒ 52341 × σ–1 ←
15234 × δ ⇒ 23451 × σ–1 ← back to start
We note two things: the original first entry, 1, just shuttles back and forth between the first and last position. And the other entries, 2345, are always in the same cyclic order if we drop the 1 and just pay attention to what’s left. So, given any choice of n–1 symbols in a particular cyclic order, we can construct an alternating cycle by placing the missing symbol at the start and then multiplying by δ and σ–1 in turn. The specific alternating cycle we get will not depend on the precise order in which the n–1 symbols were supplied, because all n–1 rotations will appear somewhere in the same cycle.
Williams proves that any cycle cover of our graph can be constructed in the following way: choose some set (possibly the empty set) of alternating cycles with disjoint edges. Then take all the weight-1 edges in the graph, throw away any that appear in our choice of alternating cycles, and in their place use the weight-2 edges from the same alternating cycles.
Why does this give us a cycle cover? When we start with just the weight-1 edges, we know they form a cycle cover, comprised of all the 1-cycles. For each weight-1 edge we throw away because it appears in an alternating cycle, there are two vertices affected: the one at the start of the edge and the one at the beginning. But the one at the beginning, when it loses a weight-1 edge that leaves it, gains a weight-2 edge from the alternating cycle that leaves the same vertex. And the one at the end, when it loses a weight-1 edge that reaches it, gains a weight-2 edge from the alternating cycle that reaches the same vertex.
To form a cycle cover containing just two cycles, our version of the construction goes as follows: take the n–1 pairs of cyclically consecutive digits (1,2), (2,3), ..., (n–2, n–1), (n–1, 1), and call them (r, m). For each (r, m), take the (n–3)! permutations of the symbols between 1 and n–1 that do not include (r, m), and call these strings q. Then for each of these (n–1) (n–3)! possibilities, generate the alternating cycle we get by starting at mnrq.
These (n–1) (n–3)! cycles will all be disjoint. Whenever m and r are the same the nrq will be distinct modulo rotations because of the different q. Whenever m and r are different we can’t have something like m1rot(nr1q1) = rot(nr2q2)m2 [where by rot we mean any rotation], because rotations that matched up the n on each side would necessarily match up the unequal r1 and r2.
In total, these alternating cycles will contain:
When we take the n! weight-1 edges in the graph and discard the ones from the alternating cycles, we end up with a cycle cover containing:
This means that the total weight associated with all of the edges in the cycle cover will be:
n! + (n–1)2 (n–3)!
= n! + [(n–1)(n–2) + (n–2) + 1] (n–3)!
= n! + (n–1)! + (n–2)! + (n–3)!
Now, Williams goes on to prove that this particular cycle cover contains exactly two cycles. His proof is quite long, so we won’t repeat it here. But if we take that for granted, we can now easily see how to construct a Hamiltonian path from these two cycles. The steps are:
What is the length of the superpermutation we obtain this way? Our cutting and splicing of the loops discards two weight-2 edges and adds one weight-1 edge, which reduces the overall weight by 3. And in addition to the edge weights, we need to include the length of the initial permutation in our string. So we have a total length for this construction of:
L2(n) = n! + (n–1)! + (n–2)! + (n–3)! + n – 3
You can download the source code for a command-line C program that generates superpermutations with this method: SuperPermutations.c
As well as the construction via alternating cycles, Williams states some simple local rules for determining the edges in his cycle covers. We can adapt his rules to our own choice of generating permutations, and they actually turn out to be even simpler.
Given any permutation of 1 ... n:
For example, the only permutations followed by weight-2 edges in our cycle cover for n=4 are:
| 1243 | f=1 | 1 + ((f–2) mod (n–1)) = 3 |
| 1324 | ditto | |
| 1432 | ditto | |
| 2134 | f=2 | 1 + ((f–2) mod (n–1)) = 1 |
| 2341 | ditto | |
| 2413 | ditto | |
| 3142 | f=3 | 1 + ((f–2) mod (n–1)) = 2 |
| 3214 | ditto | |
| 3421 | ditto | |
These edge rules will send any permutation either around a small cycle of length (n–1)(n–2), or a large cycle that contains all the other permutations.
The elements of the small cycle can be characterised by the rules:
Note that we have n–1 choices for the first digit f, and then the only freedom that remains is which of n–2 slots (neither the first nor the last) we choose for n. So the total number of permutations is (n–1)(n–2).
The small cycle has a regular pattern of edge weights, comprising runs of n–3 edges of weight 1 followed by a single edge of weight 2, with the pattern repeated n–1 times. For example, the small cycle in our cycle cover for n=5 has the 12 permutations:
14352 →
43521 →
35214 ⇒
21453 →
14532 →
45321 ⇒
32154 →
21543 →
15432 ⇒
43251 →
32514 →
25143 ⇒
Each weight-1 edge shifts the position of n one place to the left, within the allowed n–2 slots, until it gets as far left as allowed and we need a weight-2 edge to move it back to the right. In each block of n–2 vertices between the weight-2 edges, n occupies the same cyclic position with respect to the other n–1 digits, but then at each weight-2 edge the digit to the right of n is cyclically increased.
If we replace any of the weight-2 edges in the small cycle with a weight-1 edge, that new edge will always take us out of the small cycle into the large cycle (since it will shift n from the second slot into the first slot). So this provides us with a systematic method for choosing where to cut and stitch the two loops together:
p = n–1, n–2, ..., 3, 2, n, 1Clearly this satisfies the rules for lying in the small cycle.
q = 1, n, n–1, n–2, ..., 3, 2This satisfies the rules for lying in the small cycle, and also the rules for being followed by a weight-2 edge. So it is the predecessor of p in the small cycle, reaching it with a weight-2 edge.
r = n, n–1, n–2, ..., 3, 2, 1This is clearly not in the small cycle, so it must be in the large cycle. So now we move around the large cycle until we have visited every permutation.
In much of the work that has been done with superpermutations, it is a common practice to start at the identity permutation, 1245...n. But we can easily convert the results of this method to start there, just by renumbering all the digits accordingly.
You can download some JavaScript code that generates superpermutations with this method: Supermutate.js
A third way in which we can understand our version of the Williams construction is via the notion of 2-cycle graphs. By a 2-cycle, we mean a cycle in the permutations graph where the successive permutations are connected by a repeating pattern of one weight-2 edge followed by n–1 weight-1 edges. The product of all these edges, as permutations themselves, is δ σn–1 = δ σ–1, which as we have already seen amounts to a left rotation of the last n–1 entries of the permutation, leaving the first entry untouched. So after repeating this pattern of edges n–1 times, visiting a total of n(n–1) permutations, the cycle returns to its starting point. For example, for n=4, if we start with a weight-2 edge leaving 1234:
1234 ⇒ 3421 → 4213 → 2134 →
1342 ⇒ 4231 → 2314 → 3142 →
1423 ⇒ 2341 → 3412 → 4123 → back to start
In the standard recursive construction, the superpermutation consists of (n–2)! disjoint 2-cycles strung together, each one starting from the first weight-1 edge in the pattern, and where the final weight-2 edge that would close the cycle is replaced by a suitable edge of higher weight that moves to the next 2-cycle in the sequence.
Each 2-cycle can be characterised by the choice of the first entry of the permutations from which there are weight-2 edges, and a cyclic order for the remaining n–1 entries. We will write a 2-cycle with the notation m|q, where m is the first entry and q gives the remaining part, which can be rotated freely without changing the 2-cycle. For example, the 2-cycle shown above is 1|234 = 1|342 = 1|423. We can make a standard choice of the 2-cycle label by rotating q so that the lowest digit it contains appears first, but sometimes it will be convenient to rotate it into other positions.
The permutations that lie in the 2-cycle m|q are precisely those of the form:
rot(m rot(q))
where by rot we mean any rotation. The rotations of q take us to each of the permutations m rot(q) that are followed by a weight-2 edge, while the rotations of the whole permutation take us to the permutations followed by weight-1 edges, since traversing a weight-1 edge corresponds to a left rotation.
When are two 2-cycles, m1|q1 and m2|q2 disjoint, and when do they intersect?
m1|q1 = m1|m2r1That is, we rotate q1 so that m2 appears first, and rotate q2 so that m1 appears first.
m2|q2 = m2|m1r2
In the standard recursive construction, the (n–2)! disjoint 2-cycles that are cut and spliced with higher-weight edges all share the same m, while having distinct values for q. If we choose to have a run of n–1 weight-1 edges starting from 123...n, then m=n for all the 2-cycles, and the first few 2-cycles are:
n|1234...(n–2)(n–1)
n|1(n–1)234...(n–2)
n|12(n–1)34...(n–2)
n|123(n–1)4...(n–2)
In our version of Williams’s construction, we created a cycle cover of the permutations graph from (n–1)(n–3)! alternating cycles starting from mnrq, for (r, m) the n–1 pairs of cyclically consecutive digits (1,2), (2,3), ..., (n–2, n–1), (n–1, 1), and q the (n–3)! permutations of the symbols between 1 and n–1 that do not include (r, m).
But the process of building a cycle cover from alternating cycles can be reformulated in terms of 2-cycles: if we take the (n–1)(n–3)! 2-cycles of the form m|nrq and wherever they intersect we splice them together, we end up with the same cycle cover. This is because the weight-2 edges in the alternating cycles are exactly the same as those in the 2-cycles, while the weight-1 edges in the alternating cycles are never in the corresponding 2-cycles. Specifically, after a run of n–1 weight-1 edges in a 2-cycle, if we followed one more weight-1 edge we would return to the permutation at the start of that pattern. That edge is precisely the one ruled out of the cycle cover by its membership of the alternating cycle.
How exactly do we splice together two intersecting 2-cycles? To give a concrete example, if we take the 2-cycles 1|234 and 2|143, they will intersect along the 1-cycle rot(1423) = {1423, 4231, 2314, 3142}.

In the diagram above, the shared 1-cycle is coloured in red. As soon as we encounter a shared permutation in one 2-cycle, we switch to the other 2-cycle, follow it all the way around, and then just before we would return to the point where we entered it, we switch back to the first 2-cycle, skipping over the shared 1-cycle that we have already included.
The result of this procedure is exactly the same as if we were building a cycle cover with the two alternating cycles starting at 1234 and 2143; the spliced cycle, shown as an ellipse at the bottom of the diagram, would be one of the cycles in that cycle cover. Note that the alternating cycles here have disjoint vertex sets, even though the 2-cycles intersect. The conditions for alternating cycles to have vertices in common are the same as for the corresponding 2-cycles to intersect along two 1-cycles.
To understand the final outcome of splicing a collection of 2-cycles together, we can draw the collection as a 2-cycle graph whose vertices are 2-cycles, and whose edges join any pairs of the 2-cycles that intersect. Although we get to choose the vertices of the graph, we can’t opt out of any of the edges that arise whenever the 2-cycles intersect – that is, we can’t simply ignore some intersections and refuse to splice the overlapping 2-cycles, because the result would not be a cycle cover.
Here are the 2-cycle graphs for our version of the Williams construction, for n=6 and n=7. We have omitted the labels on the 2-cycles for most of the vertices for n=7, to avoid clutter. The colours here encode the values of m in our 2-cycle notation m|q.

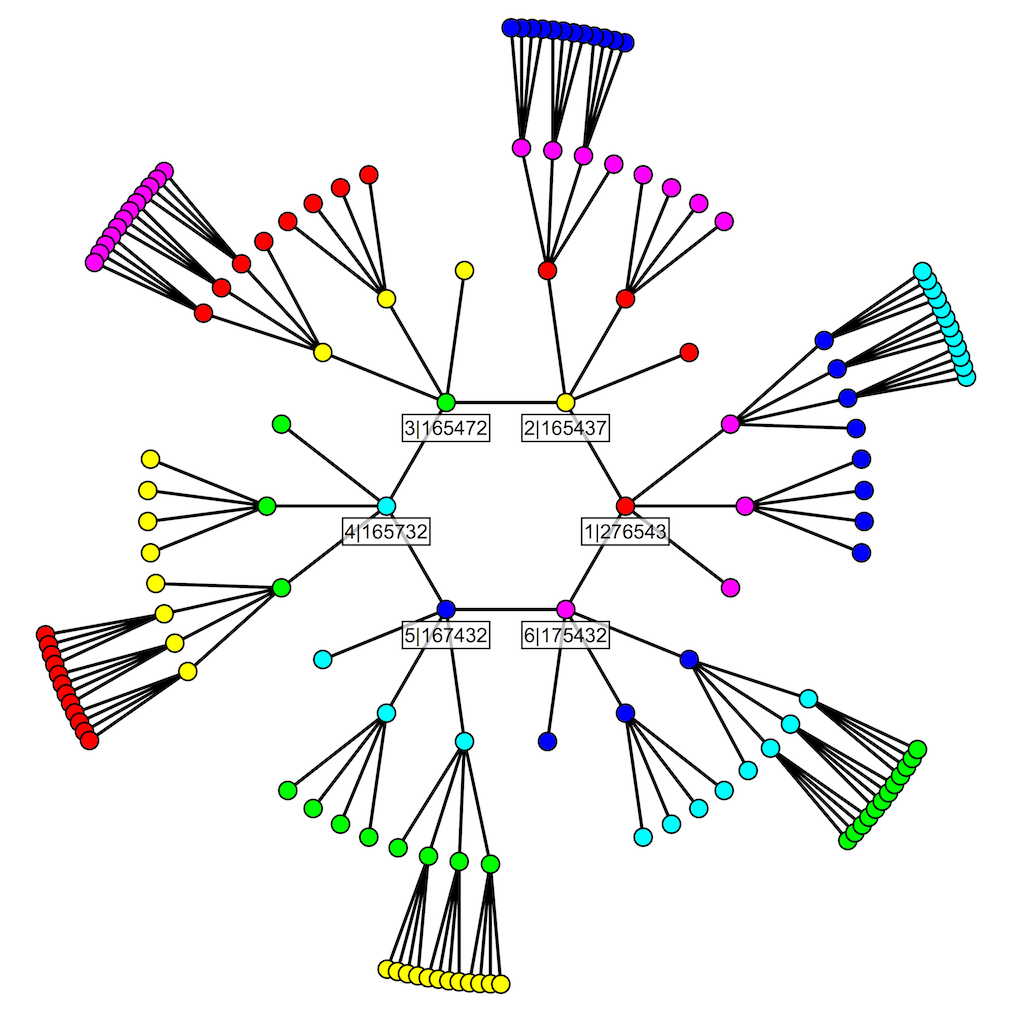
The fact that these graphs consist of a number of trees sprouting from a single polygon with n–1 vertices corresponds to the fact that the resulting cycle cover contains exactly two cycles. If we start with the polygon and splice together the 2-cycles at its vertices, one by one, we will have a single, ever-larger cycle of permutations ... until we come back to where we started, and we are splicing part of the cycle back onto itself. At that point, it splits into two cycles. One is the smaller of the two cycles in the final cover, and it plays no more part in the splicing process. The other is successively enlarged by all of the splicing operations encoded by the surrounding trees, and because (unlike the central polygon) these parts of the 2-graph contain no more loops, the subsequent splices leave the growing cycle as a single cycle right to the end.
We can picture this in a stylised fashion with the image below. Here, the small cycle is the inner boundary of the grey region, and the large cycle is the outer boundary.
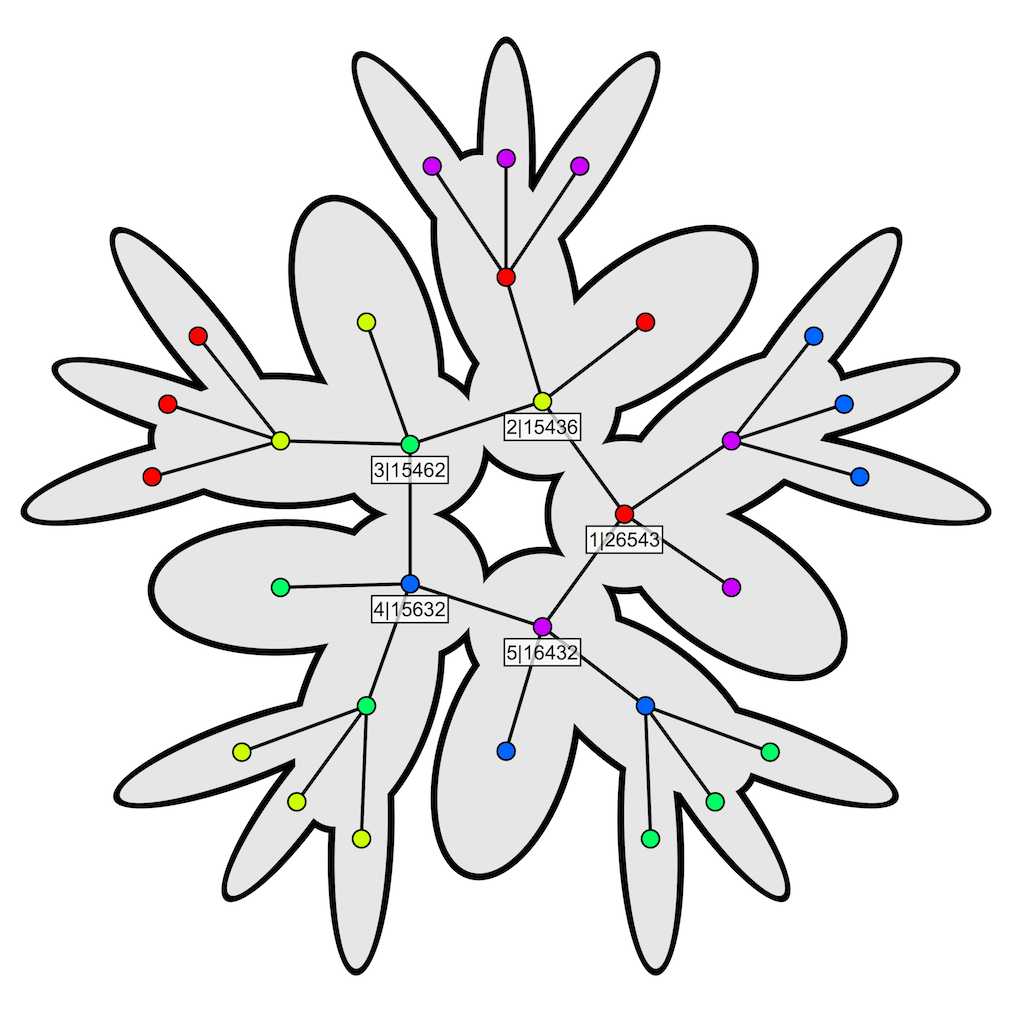
The rules for constructing the vertices for the polygon, and for building the attached trees, are reasonably simple. To construct the polygon:
To move down the tree rooted at a polygon vertex, we follow these rules:
That the children and parents in this tree have single intersections between their 2-cycles is true by construction, so to confirm that the graph will always consist of n–1 trees rooted at the vertices of an (n–1)-gon amounts to checking that there are no other edges than the ones we have described.
In our version of the Williams construction, there are (n–1) (n–3)! 2-cycles of the form m|nrq, where (r,m) are one of the n–1 choices from (1,2), (2,3), ..., (n–2, n–1), (n–1, 1), and q is any permutation of the remaining digits. We will abuse notation slightly and write r = m–1, with the cyclic wrapping from 1 to n–1 implied, so we can write m|n(m–1)q.
For two 2-cycles to intersect, they must start with different m values, so suppose we have m1|n(m1–1)q1 and m2|n(m2–1)q2, with m1 ≠ m2. Since m and m–1 never equal n, we are left with the following possibilities:
m2 | (m2–1)q2nUsing our rules for 2-cycle intersections, there will be a single intersection if and only if bn(m2–2)a and q2n are the same modulo rotation, i.e. when q2 = (m2–2)ab. This means our 2-cycles are of the form:
(m2–1) | m2bn(m2–2)a
m2 | (m2–1)(m2–2)abnThe first of these takes the form we described above for the parent in a tree, m|(m–1)p, if we put m = m2 and p = (m2–2)abn, with the second then its ℓth child, (m–1)|m rotℓ(p), where ℓ = 1+|a|. Note that |a| + |b| = n–4, so the possible range for ℓ is from 1 to n–3.
(m2–1) | m2bn(m2–2)a
(m–1) | n(m–2)amb →In words: if we have (m–1) to the left of the bar, and we have written the right-hand portion starting with n, we extract m from the right part and place it on the left, and put (m–1) after n on the right. If we continue this process, and use a sequence of modified strings a' etc. to maintain a uniform pattern, we have:
m | n(m–1)(m–2)ab
(m–1) | n(m–2)amb →So whatever the original a and b were, the combined length of the primed versions is reduced by 1 at each step, and after n–4 steps at most, we end up with precisely the descending sequence form of a root vertex.
m | n(m–1)(m–2)a'(m+1)b' →
(m+1) | nm(m–1)(m–2)a''(m+2)b'' →
(m+2) | n(m+1)m(m–1)(m–2)a'''(m+3)b''' → ...
m1 | n(m1–1)a1m2b1or, if we rotate them into a suitable form to check for intersections:
m2 | n(m2–1)a2m1b2
m1 | m2b1n(m1–1)a1But these 2-cycles can never intersect, as the different digits to the right of n in the two cases mean that b1n(m1–1)a1 and b2n(m2–1)a2 can never be the same modulo rotation.
m2 | m1b2n(m2–1)a2
On 1 February 2019, “Charlie Vane” discovered a superpermutation for n=7 of length 5907, a new record! This was announced in the comments section to a YouTube video on superpermutations by Matt Parker[6].
n = 7, with 5907 digits, discovered by “Charlie Vane”
Apparently “Charlie Vane” is an online handle for Bogdan Coanda, who provided an explanation of how this superpermutation was found[7].
On 27 February 2019, Robin Houston and I found a superpermutation for n=7 of length 5906, breaking the previous record.
In order to keep up the tradition of announcing superpermutations in unconventional ways, Matt Parker offered to “publish” this by having it performed by a self-playing piano at one of his events. So if you want to hear this superpermutation for yourself, rendered as music in a heptatonic scale, here are several MIDI versions to choose from:
and here is a percussive version that Robin Houston made, which sounds to me like a sample from a Radiohead song (this is an MP3, not MIDI):
(If you don’t have software for playing MIDI files, then if your computer has Java installed, you could download my QuasiMusic java app from here; full instructions for using the app are here, but for this purpose you can just ignore all of the app’s controls other than the PLAY MIDI FILE button.)
And if you want to see the digits, here they are:
How was this superpermutation found? Some quick backstory first. Ever since Robin Houston found the shortest superpermutation for n=6 via a Travelling Salesman solver, he and several collaborators have been trying to understand and generalise the structure of that superpermutation (and the thousands of others he later found of the same length).
Until recently, the state of the art here was to start with a portion of the standard superpermutation for the same value of n, consisting of a number of whole 3-cycles. Each 3-cycle is a sequence of (n–2) 2-cycles connected by edges of weight 3, while consecutive 3-cycles are joined to each other by edges of weight 4. By taking this initial “kernel” and then merging it with a succession of 2-cycles, it turns out to be possible to visit every permutation, at least for n=6 and n=7, with a total length of:
L3(n) = n! + (n–1)! + (n–2)! + (n–3)! + n – 4
This is one better than the superpermutations I built using a variation on a construction by Aaron Williams[5], but so far it is still just an empirical result relying on computer searches for these specific values of n; no one has proved that it can always be achieved for arbitrary n.
The current breakthrough came when Robin Houston realised that there are alternative, “non-standard kernels” we could use instead of the ones based on the standard superpermutation, and some of these had the potential to make the final result even shorter. He generated a list of candidate kernels, and I adapted a search program I’d written[8] (itself based on Bogdan Coanda’s successful approach) and, amazingly enough, we found that we could take one of these kernels and complete it with 2-cycles to yield a superpermutation of length 5906, one less than L3(7)=5907.
(In case you’re wondering about n=6, Robin tried the same approach there, and while it yielded superpermutations with a different structure, thanks to the new kind of kernel, none of them were shorter than the existing record of L3(6)=872.)
One key aspect that made this search tractable was to use a palindromic kernel, and then impose the twofold symmetry of the kernel on the rest of the solution. So each time the searcher tried adding a particular 2-cycle to the solution in progress, it would automatically add a kind of mirror-image version at the same time, drastically cutting down the space of possibilities that needed to be searched.
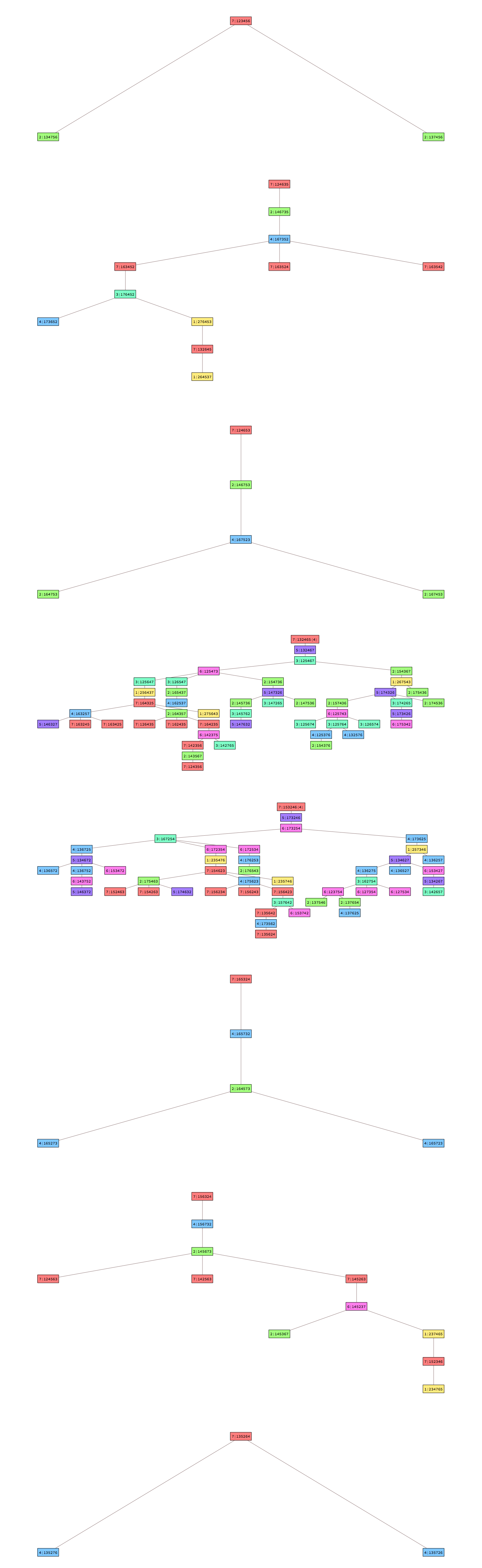
The kernel that yielded this result contains 18 parts, and is described in Robin Houston’s notation as 666646664466646666, where these digits give the number of 1-cycles visited between successive weight-3 edges. So there are 14 complete 2-cycles here, with six 1-cycles each, along with 4 incomplete ones with just four 1-cycles each.
The image on the right shows the eight trees of 2-cycles that were attached to the kernel to yield the superpermutation; this is the same kind of diagram as the 2-cycle graphs discussed previously, except for two aspects: for incomplete 2-cycles, the number of 1-cycles is given in parentheses after the 2-cycle name, and neither the pieces of the kernel that have no 2-cycles attached, nor the weight-3 edges that link all the pieces, are shown here.
At the time of writing, we’ve found a few dozen solutions like this, and there are probably hundreds, if not thousands, more. The real challenge, of course, remains to find a way to generalise this result for any value of n. Does the improvement on the previous conjectured minimum length, L3(n), remain just 1, or does it grow even larger as n increases? Right now, nobody knows!
[1] “The Minimal Superpermutation Problem”, Nathaniel Johnston.
[2] “Non-Uniqueness of Minimal Superpermutations”, Nathaniel Johnston, Discrete Mathematics, 313:1553—1557, 2013.
[3] “All Minimal Superpermutations on Five Symbols Have Been Found”, Nathaniel Johnston.
[4] “Tackling the Minimal Superpermutation Problem”, Robin Houston.
[5] “Hamiltonicity of the Cayley Digraph on the Symmetric Group Generated by σ=(1 2 ... n) and τ=(1 2)”, Aaron Williams.
[6] Comment on Matt Parker’s Superpermutations video, “Charlie Vane”, 1 February 2019.
[7] Description of algorithm, Bogdan Coanda, 2 February 2019.
[8] PermutationChains program on GitHub, Greg Egan.